Registration & Breakfast
2025-06-07
Event
Activities tracked
104
Sessions & talks
Showing 76–100 of 104 · Newest first
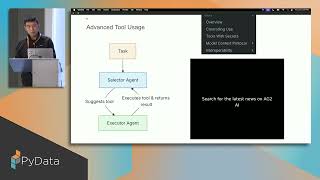
In this tutorial, we will cover basic and advanced agentic design patterns in AG2 and we will go through practical implementations to demonstrate AI agents in action.

Graph theory is a well-known concept for algorithms and can be used to orchestrate the building of multi-model pipelines. By translating tasks and dependencies into a Directed Acyclic Graph, we can orchestrate diverse AI models, including NLP, vision, and recommendation capabilities. This tutorial provides a step-by-step approach to designing graph-based AI model pipelines, focusing on clinical use cases from the field.
Reinforcement Learning (RL) has emerged as a transformative sub-field in AI/ML, driving breakthroughs in areas ranging from autonomous robotics to personalized recommendation systems. This workshop is designed to serve a broad audience—from beginners eager to grasp foundational RL concepts to practitioners seeking to deepen their technical expertise through applied projects. These projects will range from developing simple classical RL game environments to practical financial domain use cases such as using RL sequential decision making for stock trading and asset portfolio optimization scenarios.

In this 90-minute workshop, machine learning engineers and data scientists will learn practical techniques for identifying and mitigating age bias in AI-driven hiring systems. We’ll explore fairness metrics like statistical parity, counterfactual fairness, and equalized odds, and demonstrate how tools such as Fairlearn, Aequitas, and AI Fairness 360 can be used to monitor and improve model fairness. Through hands-on exercises, participants will walk away with the skills to evaluate and de-bias models in high-risk areas like recruitment.
This workshop is designed for Python developers eager to explore the exciting world of quantum computing. Through interactive exercises and practical coding examples, participants will learn how to program quantum computers using Python. No advanced background in quantum mechanics is required - just curiosity and a willingness to dive into cutting-edge technology.
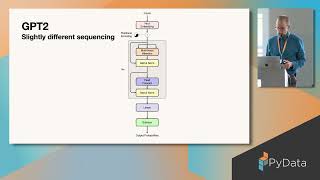
Large Language Models like GPT4 are now a key part of the technology landsacpe, but how do they really work? And can you code them up at home? In this tutorial we'll create a simple GPT and train it on a simplified dataset of children's jokes. We'll work against a new set of transformer encoder flow diagrams that intuitively match the code, and look at visualisations of GPT's internal representations in order to better understand transformers inside out!

This hands-on workshop covers how to use open source ML models like LSTMs and TimeSeries LLM's, with Python to try to forecast weather patterns, with best practices for data preparation and real time predictions.

Learn how to transform your Python code into a command-line tool. Jeroen Janssens, author of Data Science at the Command Line, guides you through the process of turning your scripts into reusable, executable tools, integrating them into your data workflows and harnessing the power of the Unix command line.

Accelerating Python using the GPU is much easier than you might think. We will explore the powerful CUDA-enabled Python ecosystem in this tutorial through hands-on examples using some of the most popular accelerated scientific computing libraries.
Topics include: - Introduction to General Purpose GPU Computing - GPU vs CPU - Which processor is best for which tasks - Introduction to CUDA - How to use CUDA with Python - Using Numba to write kernel functions - CuPy - cuDF
No prior experience with GPU's is necessary, but attendees should be familiar with Python.
You've probably heard the name Apache Iceberg by now. If it wasn't when Databricks reportedly spent 2 billion USD buying Tabular, it might have been when AWS announced S3 Tables built on Iceberg. But do you know what Apache Iceberg actually is? Or how you could start using it today?
In this tutorial, we will walk through an end-to-end example of writing and reading Iceberg data, while taking a few pitstops to demonstrate Iceberg's selling points.
Time series data is ubiquitous, from stock market prices and weather patterns to disease outbreaks and sports outcomes. Accurately modeling these data and generating useful predictions requires specialized techniques due to the unique characteristics of time series data. This tutorial provides a practical introduction to Bayesian time series analysis using PyMC, a powerful probabilistic programming library in Python. Participants will learn how to build, evaluate, and interpret various Bayesian time series models, including ARIMA models, dynamic linear models, and stochastic volatility models. We'll emphasize practical application, covering data preprocessing, model selection, diagnostics, and forecasting, empowering attendees to tackle real-world time series problems with confidence.