Networking and Drinks
2025-12-09
Event
Activities tracked
55
Sessions & talks
Showing 1–25 of 55 · Newest first
Closing
Closing Keynote
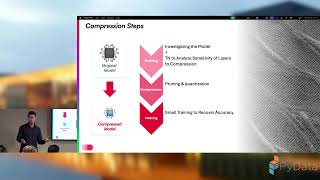
Large AI models have become powerful but increasingly impractical; with escalating training costs, bloated memory requirements, and latency bottlenecks that limit real-world deployments. This talk introduces CompactifAI: a quantum-inspired compression framework that uses tensor networks to surgically shrink large models while preserving their accuracy and capabilities.
Modern defense systems operate in environments that change by the second. To keep up, they need more than static maps and siloed data, they need true situational awareness. This talk explores how we are building a Responsible Human-Agent Ecosystem that combines high-resolution 3D geospatial data, real-time sensor fusion, and AI-driven agents to help mission-critical platforms understand the world the way humans do- but faster and at scale.

AI teams iterate at the speed of innovation, while organizations require platforms that are reliable, governed, and cost‑efficient. This session presents pragmatic patterns and reference architectures that align rapid development with production requirements—so data scientists and developers can move fast without breaking stability.
Designing an ML model is one thing; designing an ML system that actually solves a business problem is another.
This talk explores how ML system design bridges the gap between a model and a real solution. Through practical examples, we’ll look at how communication with stakeholders, understanding functional and non-functional requirements, and aligning optimization and evaluation with business needs determine whether an ML initiative succeeds or stalls.
We’ll highlight key decision points — from translating vague goals into measurable objectives to balancing model performance with constraints like latency, interpretability, and maintainability.
Attendees will walk away with a sharper view of what makes an ML system truly fit for its environment — and why good design matters as much as good modeling.
Fantasy basketball involves daily decisions: which players to start, who to pick up from free agency, and how to balance competing objectives across multiple statistical categories. This talk demonstrates how linear programming and integer programming can help solving those problems.
Using Python library PuLP we'll explore when to use linear programming versus integer programming, how to formulate constraints for roster decisions, and how to handle different league formats. Through practical examples, we'll build optimizers for start/sit decisions and free agency streaming.

This session delivers a blueprint for building, deploying, and managing agents in a secure, scalable, and cost-effective manner on Google Cloud, bridging the critical gap between development and operations.
Have you ever happened to use GPS and realised that it is not working properly? The Sun and a Space Weather effect called Travelling Ionospheric Disturbances (TIDs) could be responsible. We will present an explainable TIDs forecasting model, based on CatBoost and using several physical drivers to make forecasts.
How can data science help young athletes navigate their careers? In this talk, I’ll share my experience building a career path planner for aspiring ice hockey players. The project combines player performance data, career path patterns, and predictive modeling to suggest possible development paths and milestones. Along the way, I’ll discuss the challenges of messy sports data and communicating insights in a way that resonates with non-technical users like coaches, parents, and players.
What if your database could run Python code inside SQL? In this talk, we’ll explore how to extend popular databases using Python, without needing to write a line of C.
We’ll cover three systems—SQLite, DuckDB, and PostgreSQL—and show how Python can be used in each to build custom SQL functions, accelerate data workflows, and prototype analytical logic. Each database offers a unique integration path: - SQLite and DuckDB allow you to register Python functions directly into SQL via sqlite3.create_function, making it easy to inject business logic or custom transformations. - PostgreSQL offers PL/Python, a full-featured procedural language for writing SQL functions in Python. We’ll also touch on advanced use cases, including embedding the Python interpreter directly into a PostgreSQL extension for deeper integration.
By the end of this talk, you’ll understand the capabilities, limitations, and gotchas of Python-powered extensions in each system—and how to choose the right tool depending on your use case, whether you’re analyzing data, building pipelines, or hacking on your own database.