Tristan Handy
(CEO and Founder)
 talk-data.com
talk-data.com
Company
dbt Labs
Speakers
51
Activities
44
Speakers from dbt Labs
Faith McKenna
Lead Technical Instructor
5
Akash Trivedi
Senior Technical Instructor
3
Jerrie Kumalah Kenney
Resident Architect
3
Alex Talbott
Senior Data Analyst
2
Ani Venkateshwaran
Software Engineer
2
Bolaji Oyejide
Digital Community Engagement Manager
2
Carly Kaufman
Regional Director of Professional Services
2
Charlotte Maupu
Resident Architect
2
Connie Carey
Senior Product Manager, Growth
2
Elias DeFaria
Staff Product Manager
2
Erica Faulkenberry
Customer Solutions Architect
2
Jenna Bushspies
Senior Technical Instructor
2
Roxi Dalhke
Product Manager
2
Sara Gawlinski
Technical Product Marketing Manager
2
Stephen Thibeault
Resident Architect
2
Ben Butler
Customer Solutions Architect
1
Chris Fiore
Senior Data Analyst
1
Cormac Buckley
Senior Customer Solutions Architect
1
Elisha Feliciano
Strategic Events Manager
1
Jamie Nemeroff
Lead Value Engineer
1
Talks & appearances
44 activities from dbt Labs speakers

Delivering trusted data at scale doesn’t have to mean ballooning costs or endless rework. In this session, we’ll explore how state-aware orchestration, powered by Fusion, drives leaner, smarter pipelines in the dbt platform. We’ll cover advanced configurations for even greater efficiency, practitioner tips that save resources, and testing patterns that cut redundancy. The result: faster runs, lower spend, and more time for impactful work.
Continue the conversation from Building High-Quality AI Workflows with the dbt MCP Server in this interactive roundtable. We’ll explore how dbt’s MCP Server connects governed data to AI systems, dive deeper into the practical use cases, and talk through how organizations can adopt AI safely and effectively. This is your chance to: Ask detailed technical questions and get answers from product experts. Share your team’s challenges and learn from peers who are experimenting with MCP. Explore what’s possible today and influence where we go next. Attendance at the breakout session is encouraged but not required. Come ready to join the discussion and leave with new ideas!
Join us for a roundtable discussion where we’ll go deeper into the ideas shared in the dbt development in the age of AI: Improving the developer experience in the dbt platform. Bring your questions, share your take, and connect with peers and presenters. Note attendance in the breakout session is not required.
This workshop will cover new analyst focused user interfaces in dbt. Understand how to develop in dbt Canvas, how to explore within the Insights query page, and how to navigate across your data control plane in the dbt Catalog. What to bring: You will need to bring your own laptop to complete the hands-on exercises. We will provide all the other sandbox environments for dbt and a data platform.

Jeremy Cohen
(Head of Data Strategy, Investment Bank)
Iceberg is an open storage format for large analytical datasets that is now interoperable with most modern data platforms. But the setup is complicated, and caveats abound. Jeremy Cohen will tour the archipelago of Iceberg integrations — across data warehouses, catalogs, and dbt — and demonstrate the promise of cross platform dbt Mesh to provide flexibility and collaboration for data teams. The more the merrier.
Join us for a roundtable discussion where we’ll go deeper into the ideas shared in the Turn metadata into meaning: Build context, share insights, and make better decisions with dbt Catalog breakout. Bring your questions, share your take, and connect with peers and presenters. Note attendance in the breakout session is not required.
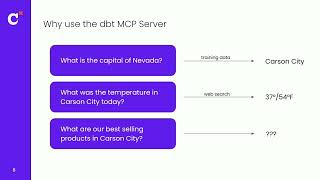
Modern data teams are tasked with bringing AI into the analytics stack in a way that is trustworthy, scalable, and deeply integrated. In this session, we’ll show how the dbt MCP server connects LLMs and agents to structured and governed data to power use cases for development, discovery, and querying.
dbt Mesh allowed for monolithic dbt projects to be broken down into more consumable and governed smaller projects. Now, learn how cross-platform mesh will allow you to take this one step further with development across data platforms using Iceberg tables. After this course you will be able to: Identify ideal use cases dbt Mesh Configure cross-project references between data platforms Navigate dbt Catalog Prerequisites for this course include: dbt Fundamentals, specifically data models and building model dependencies dbt Model governance Various data platforms What to bring: You will need to bring your own laptop to complete the hands-on exercises. We will provide all the other sandbox environments for dbt and data platform. Duration : 2 hours Fee : $200 Trainings and certifications are not offered separately and must be purchased with a Coalesce pass. Trainings and certifications are not available for Coalesce Online passes.
This course will focus on leveraging the semantic layer to build and consume metrics from dbt. We will start with an initial dbt project and leverage dbt Copilot to create the necessary logic to power your semantic layer. After defining and building these assets, we will configure partner tools to utilize single source of truth reporting: driving collaboration across data consumers in your team. Prerequisites: The prerequisites for this course include: dbt Fundamentals, specifically data modeling and model configurations What to bring: You will need to bring your own laptop to complete the hands-on exercises. We will provide all the other sandbox environments for dbt and a data platform.
Join us for a roundtable discussion where we’ll go deeper into the ideas shared in the Shaping the future of self-service with the dbt MCP server and Semantic Layer breakout. Bring your questions, share your take, and connect with peers and presenters. Note attendance in the breakout session is not required.
Luis Leon
(Partner Solution Architect)
See how AI is shaping developer tools for the next generation. AWS Kiro provides a powerful general purpose IDE great for a wide variety of programming languages and tasks. Pairing Kiro with the dbt MCP Server makes this even more powerful by providing access to dbt specific functionality, context and agents. In addition to this, interact with an external agent deployed in Amazon Bedrock AgentCore.
Jerrie and Faith have developed a framework for thoughtful, effective data testing and QA. In this peer exchange, attendees will battle-test the framework by sharing where it fits across industries. Attendees will walk away with their own testing framework to try in their day jobs.

Grace Goheen
(Product Manager)
The dbt language is growing to support new workflows across both dbt Core and the dbt Fusion engine. In this session, we’ll walk through the latest updates to dbt—from sample mode to iceberg catalogs to UDFs—showing how they work across different engines. You’ll also learn how to track the roadmap, contribute to development, and stay connected to the future of dbt.

Discover how dbt Catalog brings structure and clarity to your data ecosystem by turning metadata into a powerful asset. In this session, we’ll dive into how the dbt Catalog helps data teams and their stakeholders explore, trust, and act on data faster—by connecting lineage, documentation, and usage in one place. Learn what’s available today, what’s coming next, and how dbt Catalog fits into the broader vision for metadata in the AI era.
Learn how dbt is evolving with the next-generation engine powered by Fusion. In this hands-on session, you'll explore how Fusion improves dbt’s performance, enables richer SQL parsing, and sets the stage for future enhancements like better refactoring tools and faster development workflows.What to bring: You must bring your own laptop to complete the hands-on exercises. We will provide all the other sandbox environments for dbt and a data platform.
Step into a dynamic, interactive session where you'll experience the data transformation journey from multiple angles: Data Engineer, Manager, Analytics VP, and Chief Data Officer. This immersive tabletop exercise isn’t your typical panel or demo—it’s a high-empathy, scenario-driven experience designed to build cross-role understanding and alignment across the modern data stack. Each scene drops you into a real-world challenge—whether it's data trust issues, managing cost pressures, or preparing for an AI initiative—and forces a go/no-go decision with your peers. You’ll explore how your choices impact others across the org, from the technical trenches to the boardroom. Whether you're a practitioner, leader, or executive, this session will help you see data not just as pipelines and dashboards, but as a 360-degree opportunity to drive business change. Walk away with a clear picture of the capabilities your team needs (without naming products) and a roadmap for building champions across your org.
Delve into the core concepts and applications of data quality with dbt. With a focus on practical implementation, you'll learn to deploy custom data tests, unit testing, and linting to ensure the reliability and accuracy of your data operations. After this course, you will be able to: Recognize scenarios that call for testing data quality Implement efficient data testing methods to ensure reliability (data tests, unit tests) Navigate other quality checks in dbt (linting, CI, compare) Prerequisites for this course include: dbt Fundamentals What to bring: You will need to bring your own laptop to complete the hands-on exercises. We will provide all the other sandbox environments for dbt and data platform. Duration: 2 hours Fee: $200 Trainings and certifications are not offered separately and must be purchased with a Coalesce pass Trainings and certifications are not available for Coalesce Online passes
Faith McKenna
(Lead Technical Instructor)
,
Carly Kaufman
(Regional Director of Professional Services)
dbt Canvas makes it simple for every data practitioner to contribute to a dbt project. Learn the foundational concepts of developing in Canvas, dbt's new visual editor, and the best practices of editing and creating dbt models. After this course, you will be able to: Create new dbt models and edit existing models in dbt Canvas Understand the different operators in Canvas Evaluate the underlying SQL produced by Canvas Prerequisites for this course include: Basic SQL understanding What to bring: You will need to bring your own laptop to complete the hands-on exercises. We will provide all the other sandbox environments for dbt and data platform. Duration: 2 hours Fee: $200 Trainings and certifications are not offered separately and must be purchased with a Coalesce pass Trainings and certifications are not available for Coalesce Online passes
In this session, you’ll learn how dbt’s Semantic Layer and MCP Server enable safe, AI-powered access to data through natural language interfaces. As business users start exploring data conversationally, the analyst role is evolving—from writing queries to curating trusted logic, guiding usage, and enabling scalable self-service. We’ll break down what this shift looks like and how dbt helps analysts stay at the center of decision-making.
Tristan Handy
,
Grace Goheen
(Product Manager)
,
Elias DeFaria
(Staff Product Manager)
,
Jeremy Cohen
(Head of Data Strategy, Investment Bank)
,
Bolaji Oyejide
(Digital Community Engagement Manager)
Let’s bring it back to where it all began—with you, the dbt community—and to where we’re going. We’ll share our perspective on how the two engines, dbt Core and Fusion, are united by one common framework—and how we continue to build in the open. Plus: recognition of our exceptional community contributors who make dbt so special. For our Coalesce Online attendees, join us on Slack in #coalesce-2025 to stay connected during keynote!

Russell Christopher
(Sr. Director, Product Management)
The future of AI is here. Join AI and data industry thought leader Ashley Kramer from OpenAI as she shares how AI-powered development and intelligent systems act as force multipliers for organizations—and how to confidently embrace these accelerants at scale. In the second half of the keynote, she'll be joined by a panel of product leaders from across the data stack for a discussion on the future of analytics in an AI-driven world and how dbt and ecosystem partners are innovating to rewrite what’s possible: turning yesterday's science fiction into today's reality. For our Coalesce Online attendees, join us on Slack in #coalesce-2025 to stay connected during keynote!

Learn why dbt is the best place for analysts to build reliable data products quickly, combining structured workflows with context-aware AI. We will explore how dbt Canvas, dbt Studio, and more give analysts the visibility, control, and flexibility they need to move from exploration to production without relying on engineers. You will also see how AI agents in dbt accelerate development by recommending logic, surfacing relevant models, and helping troubleshoot issues—making self-service both faster and more trusted.
Join us for a roundtable discussion where we’ll go deeper into the ideas shared in the Next-gen data development with dbt Fusion engine breakout. Bring your questions, share your take, and connect with peers and presenters. Note attendance in the breakout session is not required.
Get hands-on with dbt Copilot, the AI assistant built into dbt that helps you move faster and write better code. In this workshop, you’ll learn how to use copilot to generate sql, create data tests and documentation, and build semantic models and metrics —all within your existing workflow. What to bring: You must bring your own laptop to complete the hands-on exercises. We will provide all the other sandbox environments for dbt and data platform.