AI/ML workloads depend heavily on complex software stacks, including numerical computing libraries (SciPy, NumPy), deep learning frameworks (PyTorch, TensorFlow), and specialized toolchains (CUDA, cuDNN). However, integrating these dependencies into Bazel-based workflows remains challenging due to compatibility issues, dependency resolution, and performance optimization. This session explores the process of creating and maintaining Bazel packages for key AI/ML libraries, ensuring reproducibility, performance, and ease of use for researchers and engineers.
 talk-data.com
talk-data.com
Topic
NumPy
scientific_computing
numerical_analysis
python
2
tagged
Activity Trend
16
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Science Books
41
SciPy 2025
11
O'Reilly Data Visualization Books
8
O'Reilly Data Engineering Books
6
ADSP: Algorithms + Data Structures = Programs
3
PyData Paris 2025
3
PyConDE & PyData Berlin 2023
2
PyData Seattle 2025
2
Data Engineering Podcast
2
Introduction AI Mini Bootcamp - Dr. Yasin Ceran
1
[Online] Contributing to the NumPy Documentation
1
PyData Paris 2024
1
Filtering by:
PyData Seattle 2025
×
by
Andy Terrel
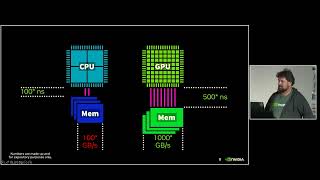
The world of generative AI is expanding. New models are hitting the market daily. The field has bifurcated between model training and model inference. The need for fast inference has led to numerous Tile languages to be developed. These languages use concepts from linear algebra and borrow common numpy apis. In this talk we will show how tiling works and how to build inference models from scratch in pure Python with embedded tile languages. The goal is to provide attendees with a good overview that can be integrated in common data pipelines.