AI/ML workloads depend heavily on complex software stacks, including numerical computing libraries (SciPy, NumPy), deep learning frameworks (PyTorch, TensorFlow), and specialized toolchains (CUDA, cuDNN). However, integrating these dependencies into Bazel-based workflows remains challenging due to compatibility issues, dependency resolution, and performance optimization. This session explores the process of creating and maintaining Bazel packages for key AI/ML libraries, ensuring reproducibility, performance, and ease of use for researchers and engineers.
 talk-data.com
talk-data.com
Topic
NumPy
scientific_computing
numerical_analysis
python
86
tagged
Activity Trend
16
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Science Books
41
SciPy 2025
11
O'Reilly Data Visualization Books
8
O'Reilly Data Engineering Books
6
ADSP: Algorithms + Data Structures = Programs
3
PyData Paris 2025
3
PyConDE & PyData Berlin 2023
2
PyData Seattle 2025
2
Data Engineering Podcast
2
Introduction AI Mini Bootcamp - Dr. Yasin Ceran
1
[Online] Contributing to the NumPy Documentation
1
PyData Paris 2024
1
Host and organizer remarks for PyData NYC Project Day.
by
Andy Terrel
The world of generative AI is expanding. New models are hitting the market daily. The field has bifurcated between model training and model inference. The need for fast inference has led to numerous Tile languages to be developed. These languages use concepts from linear algebra and borrow common numpy apis. In this talk we will show how tiling works and how to build inference models from scratch in pure Python with embedded tile languages. The goal is to provide attendees with a good overview that can be integrated in common data pipelines.
Vos modèles prédictifs vieillissent mal ? Une mise à jour de vos packages (pandas, scikit-learn, lightgbm…), et c’est la panne assurée en production…
Avec Scoring.AI, reprenez le contrôle total et garantissez leur pérennité. Notre outil innovant construit des scores hyper performants et traduit automatiquement leur déploiement en code Python pur, basé uniquement sur Pandas et NumPy.
Résultat ?
Une portabilité totale : vos modèles fonctionnent en production indépendamment des packages et outils qui ont servi à les construire
Une maintenance simplifiée : les équipes IT peuvent mettre à jour leur stack technique sans risque de casse
Propriété et transparence accrue : un code lisible, auditable et facile à déployer, même dans des environnements contraints
À travers des cas concrets et une démo live, explorez comment désenclaver vos modèles des dépendances logicielles et garantir leur survie sur le long terme. Parce qu’un bon modèle, c’est un modèle qui dure !

We all love to tell stories with data and we all love to listen to them. Wouldn't it be great if we could also draw actionable insights from these nice stories?
As scikit-learn maintainers, we would love to use PyPI download stats and other proxy metrics (website analytics, github repository statistics, etc ...) to help inform some of our decisions like: - how do we increase user awareness of best practices (please use Pipeline and cross-validation)? - how do we advertise our recent improvements (use HistGradientBoosting rather than GradientBoosting, TunedThresholdClassifier, PCA and a few other models can run on GPU) ? - do users care more about new features from recent releases or consolidation of what already exists? - how long should we support older versions of Python, numpy or scipy ?
In this talk we will highlight a number of lessons learned while trying to understand the complex reality behind these seemingly simple metrics.
Telling nice stories is not always hard, trying to grasp the reality behind these metrics is often tricky.

Behind every technical leap in scientific Python lies a human ecosystem of volunteers, companies, and institutions working in tension and collaboration. This keynote explores how innovation actually happens in open source, through the lens of recent and ongoing initiatives that aim to move the needle on performance and usability - from the ideas that went into NumPy 2.0 and its relatively smooth rollout to the ongoing efforts to leverage the performance GPUs offer without sacrificing maintainability and usability.
Takeaways for the audience: Whether you’re an ML engineer tired of debugging GPU-CPU inconsistencies, a researcher pushing Python to its limits, or an open-source maintainer seeking sustainable funding, this keynote will equip you with both practical solutions and a clear vision of where scientific Python is headed next.

The array API standard is unifying the ecosystem of Python array computing, facilitating greater interoperability between code written for different array libraries, including NumPy, CuPy, PyTorch, JAX, and Dask.
But what are all of these "array-api-" libraries for? How can you use these libraries to 'future-proof' your libraries, and provide support for GPU and distributed arrays to your users? Find out in this talk, where I'll guide you through every corner of the array API standard ecosystem, explaining how SciPy and scikit-learn are using all of these tools to adopt the standard. I'll also be sharing progress updates from the past year, to give you a clear picture of where we are now, and what the future holds.
Keynote talk by Ralf Gommers, SciPy and NumPy maintainer, director at Quansight Labs.

Maximize your portfolio, analyze markets, and make data-driven investment decisions using Python and generative AI. Investing for Programmers shows you how you can turn your existing skills as a programmer into a knack for making sharper investment choices. You’ll learn how to use the Python ecosystem, modern analytic methods, and cutting-edge AI tools to make better decisions and improve the odds of long-term financial success. In Investing for Programmers you’ll learn how to: Build stock analysis tools and predictive models Identify market-beating investment opportunities Design and evaluate algorithmic trading strategies Use AI to automate investment research Analyze market sentiments with media data mining In Investing for Programmers you'll learn the basics of financial investment as you conduct real market analysis, connect with trading APIs to automate buy-sell, and develop a systematic approach to risk management. Don’t worry—there’s no dodgy financial advice or flimsy get-rich-quick schemes. Real-life examples help you build your own intuition about financial markets, and make better decisions for retirement, financial independence, and getting more from your hard-earned money. About the Technology A programmer has a unique edge when it comes to investing. Using open-source Python libraries and AI tools, you can perform sophisticated analysis normally reserved for expensive financial professionals. This book guides you step-by-step through building your own stock analysis tools, forecasting models, and more so you can make smart, data-driven investment decisions. About the Book Investing for Programmers shows you how to analyze investment opportunities using Python and machine learning. In this easy-to-read handbook, experienced algorithmic investor Stefan Papp shows you how to use Pandas, NumPy, and Matplotlib to dissect stock market data, uncover patterns, and build your own trading models. You’ll also discover how to use AI agents and LLMs to enhance your financial research and decision-making process. What's Inside Build stock analysis tools and predictive models Design algorithmic trading strategies Use AI to automate investment research Analyze market sentiment with media data mining About the Reader For professional and hobbyist Python programmers with basic personal finance experience. About the Author Stefan Papp combines 20 years of investment experience in stocks, cryptocurrency, and bonds with decades of work as a data engineer, architect, and software consultant. Quotes Especially valuable for anyone looking to improve their investing. - Armen Kherlopian, Covenant Venture Capital A great breadth of topics—from basic finance concepts to cutting-edge technology. - Ilya Kipnis, Quantstrat Trader A top tip for people who want to leverage development skills to improve their investment possibilities. - Michael Zambiasi, Raiffeisen Digital Bank Brilliantly bridges the worlds of coding and finance. - Thomas Wiecki, PyMC Labs
In this episode, Conor and Bryce chat about language learning apps, recent C++/CUDA/Python meetups and more! Link to Episode 243 on WebsiteDiscuss this episode, leave a comment, or ask a question (on GitHub)Socials ADSP: The Podcast: TwitterConor Hoekstra: Twitter | BlueSky | MastodonBryce Adelstein Lelbach: TwitterShow Notes Date Generated: 2025-07-01 Date Released: 2025-07-18 MondlyduolingoBabbelADSP Episode 213: NumPy & Summed-Area TablesADSP Episode 227: Re: The CUDA C++ Developer’s ToolboxIntro Song Info Miss You by Sarah Jansen https://soundcloud.com/sarahjansenmusic Creative Commons — Attribution 3.0 Unported — CC BY 3.0 Free Download / Stream: http://bit.ly/l-miss-you Music promoted by Audio Library https://youtu.be/iYYxnasvfx8
This talk focuses on avenues of contribution to the project documentation, an integral part of the software.
If you have interest in NumPy, SciPy, Signal Processing, Simulation, DataFrames, Linear Programming (LP), Vehicle Routing Problems (VRP), or Graph Analysis, we'd love to hear what performance you're seeing and how you're measuring.
by
Siu Kwan Lam
The rapidly evolving Python ecosystem presents increasing challenges for adapting code using traditional methods. Developers frequently need to rewrite applications to leverage new libraries, hardware architectures, and optimization techniques. To address this challenge, the Numba team is developing a superoptimizing compiler built on equality saturation-based term rewriting. This innovative approach enables domain experts to express and share optimizations without requiring extensive compiler expertise. This talk explores how Numba v2 enables sophisticated optimizations—from floating-point approximation and automatic GPU acceleration to energy-efficient multiplication for deep learning models—all through the familiar NumPy API. Join us to discover how Numba v2 is bringing superoptimization capabilities to the Python ecosystem.
Synthetic aviation fuels (SAFs) offer a pathway to improving efficiency, but high cost and volume requirements hinder property testing and increase risk of developing low-performing fuels. To promote productive SAF research, we used Fourier Transform Infrared (FTIR) spectra to train accurate, interpretable fuel property models. In this presentation, we will discuss how we leveraged standard Python libraries – NumPy, pandas, and scikit-learn – and Non-negative Matrix Factorization to decompose FTIR spectra and develop predictive models. Specifically, we will review the pipeline developed for preprocessing FTIR data, the ensemble models used for property prediction, and how the features correlate with physicochemical properties.
This talk presents zfit with the newest improvements, a general purpose distribution fitting library for complicated model building beyond fitting a normal distribution. The talk will cover all aspects of fitting with a focus on the strong model building part in zfit; composable distributions with sums, products and more, build and mix binned and unbinned, analytic and templated functions in multiple dimensions. This includes the creation of arbitrary, custom distributions with minimal effort that fulfils everyones need. Thanks to the numpy-like backend used by TensorFlow, zfit is highly performant by using JIT compiled code on CPUs and even GPUs, a showcase for scientific computing faster than numpy.
Rydberg atoms offer unique quantum properties that enable radio-frequency sensing capabilities distinct from any classical analogue; however, large parameter spaces and complex configurations make understanding and designing these quantum experiments challenging. Current solutions are often developed as in-house, closed-sourced software simulating a narrow range of problems. We present RydIQule, an open-source package leveraging tools of computational python in novel ways to model the behavior of these systems generally. We describe RydIQule’s approach to representing quantum systems using computational graphs and leveraging numpy broadcasting to define complete experiments. In addition to discussing the computational challenges RydIQule helps overcome, we outline how collaboration between physics and computational research backgrounds has led to this impactful tool.
This keynote will trace the personal journey of NumPy's development and the evolution of the SciPy community from 2001 to the present. Drawing on over two decades of involvement, I’ll reflect on how a small group of enthusiastic contributors grew into a vibrant, global ecosystem that now forms the foundation of scientific computing in Python. Through stories, milestones, and community moments, we’ll explore the challenges, breakthroughs, and collaborative spirit that shaped both NumPy and the SciPy conventions over the years.
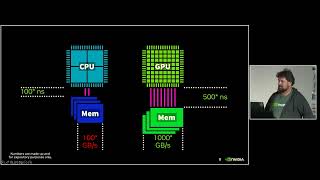
Many scientists rely on NumPy for its simplicity and strong CPU performance, but scaling beyond a single node is challenging. The researchers at SLAC need to process massive datasets under tight beam time constraints, often needing to modify code on the fly. This is where cuPyNumeric comes in—a drop-in replacement for NumPy that distributes work across CPUs and GPUs. With its familiar NumPy interface, cuPyNumeric makes it easy to scale computations without rewriting code, helping scientists focus on their research instead of debugging. It’s a great example of how the SciPy ecosystem enables cutting-edge science.
Generative Artificial Intelligence (AI) is reshaping engineering education by offering students new ways to engage with complex concepts and content. Ethical concerns including bias, intellectual property, and plagiarism make Generative AI a controversial educational tool. Overreliance on AI may also lead to academic integrity issues, necessitating clear student codes of conduct that define acceptable use. As educators we should carefully design learning objectives to align with transferrable career skills in our fields. By practicing backward design with a focus on career-readiness skills, we can incorporate useful prompt engineering, rapid prototyping, and critical reasoning skills that incorporate generative AI. Engineering students want to develop essential career skills such as critical thinking, communication, and technology. This talk will focus on case studies for using generative AI and rapid prototyping for scientific computing in engineering courses for physics, programming, and technical writing. These courses include assignments and reading examples using NumPy, SciPy, Pandas, etc. in Jupyter notebooks. Embracing generative AI tools has helped students compare, evaluate, and discuss work that was inaccessible before generative AI. This talk explores strategies for using AI in engineering education while accomplishing learning objectives and giving students opportunities to practice career readiness skills.
Cubed is a framework for distributed processing of large arrays without a cluster. Designed to respect memory constraints at all times, Cubed can express any NumPy-like array operation as a series of embarrassingly-parallel, bounded-memory steps. By using Zarr as persistent storage between steps, Cubed can run in a serverless fashion on both a local machine and on a range of Cloud platforms. After explaining Cubed’s model, we will show how Cubed has been integrated with Xarray and demonstrate its performance on various large array geoscience workloads.