An introduction to AI-DLC, a transformative approach to software development that integrates AI as a central collaborator, with three core phases: Inception, Construction, and Operations.
 talk-data.com
talk-data.com
Company
Amazon Web Services (AWS)
Speakers
13
Activities
19
Speakers from Amazon Web Services (AWS)
Suman Debnath
Principal AI/ML Advocate
6
Parnab Basak
Solutions Architect
3
Srinivas Pendyala
Solutions Architect
2
Venkatesh Aravamudan
Sr Partner Solutions Architect
2
Li-Ya Wang
AWS Solution Architect
1
Mathew Godfrey
Customer Solutions Manager
1
Noritaka Sekiyama
Principal Big Data Architect
1
Paul Le Page
Solutions Architect
1
Riya Dani
Solutions Architect
1
Sara van de Moosdijk
Solution Architect for AI/ML
1
Shweta Singh
Solutions Architect
1
Victory Uchenna
Enterprise Solutions Architect
1
Talks & appearances
19 activities from Amazon Web Services (AWS) speakers
Suman Debnath
(Principal AI/ML Advocate)
Noritaka Sekiyama
(Principal Big Data Architect)
,
Venkatesh Aravamudan
(Sr Partner Solutions Architect)
,
Neela Kulkarni
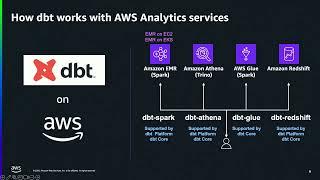
As organizations increasingly adopt modern data stacks, the combination of dbt and AWS Analytics services emerged as a powerful pairing for analytics engineering at scale. This session will explore proven strategies and hard-learned lessons for optimizing this technology stack to use dbt-athena, dbt-redshift, and dbt-glue to deliver reliable, performant data transformations. We will also cover case studies, best practices, and modern lakehouse scenarios with Apache Iceberg and Amazon S3 Tables.
See how AI is shaping developer tools for the next generation. AWS Kiro provides a powerful general purpose IDE great for a wide variety of programming languages and tasks. Pairing Kiro with the dbt MCP Server makes this even more powerful by providing access to dbt specific functionality, context and agents. In addition to this, interact with an external agent deployed in Amazon Bedrock AgentCore.
Victory Uchenna
(Enterprise Solutions Architect)
Data is one of the most valuable assets in any organisation, but accessing and analysing it has been limited to technical experts. Business users often rely on predefined dashboards and data teams to extract insights, creating bottlenecks and slowing decision-making.
This is changing with the rise of Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG). These technologies are redefining how organisations interact with data, allowing users to ask complex questions in natural language and receive accurate, real-time insights without needing deep technical expertise.
In this session, I’ll explore how LLMs and RAG are driving true data democratisation by making analytics accessible to everyone, enabling real-time insights with AI-powered search and retrieval and overcoming traditional barriers like SQL, BI tool complexity, and rigid reporting structures.
Sara van de Moosdijk
(Solution Architect for AI/ML)
A generative AI gateway is a design pattern popular in enterprise settings which establishes a central gateway where developers can access foundation models from multiple providers. It includes features for access control, quota management, cost control, governance, and observability. This session will dive deep on a recommended architecture for building an AI gateway on AWS and provide a demo of the final result.
Demonstration of building an agentic AI application to support financial analysts with a conversational AI assistant, including architectural components (Anthropic Claude 3.5 Sonnet, Amazon Bedrock, Elasticsearch Vector Database, Elasticsearch MCP Server) and capabilities such as pattern identification, linking news sentiment to portfolio performance, and real-time natural language data engagement.
Scaling Agentic AI with Claude, MCP, and Vectors. We'll focus on a financial services Agentic AI case study that empowers analysts with a conversational AI assistant built using Anthropic Claude 3.5 Sonnet on Amazon Bedrock. Elasticsearch vector database. Elasticsearch MCP (Model Context Protocol) Server. This assistant transforms complex workflows—like assessing the impact of market news on thousands of customer portfolios—into an intuitive, natural language dialogue. We'll demonstrate how to build and deploy AI Agents that help: Rapidly identify patterns in complex financial data; Build meaningful correlations, such as linking news sentiment to portfolio performance; Engage with your data in real-time, using natural language. We'll also highlight how MCP servers can integrate additional services, such as weather data and email notifications, demonstrating the power of search and generative AI.
Suman Debnath
(Principal AI/ML Advocate)
Learn how to use Deepseek effectively and integrate it into your services with live demos and step-by-step tutorials.
Suman Debnath
(Principal AI/ML Advocate)
Learn how to use Deepseek effectively and integrate it into your services with live demos and step-by-step tutorials.
Suman Debnath
(Principal AI/ML Advocate)
Suman Debnath
(Principal AI/ML Advocate)
In this session, we will focus on fine-tuning, continuous pretraining, and retrieval-augmented generation (RAG) to customize foundation models using Amazon Bedrock. Attendees will explore and compare strategies such as prompt engineering, which reformulates tasks into natural language prompts, and fine-tuning, which involves updating the model's parameters based on new tasks and use cases. The session will also highlight the trade-offs between usability and resource requirements for each approach. Participants will gain insights into leveraging the full potential of large models and learn about future advancements aimed at enhancing their adaptability.
Parnab Basak
(Solutions Architect)
In the last few years Large Language Models (LLMs) have risen to prominence as outstanding tools capable of transforming businesses. However, bringing such solutions and models to the business-as-usual operations is not an easy task. In this session, we delve into the operationalization of generative AI applications using MLOps principles, leading to the introduction of foundation model operations (FMOps) or LLM operations using Apache Airflow. We further zoom into aspects of expected people and process mindsets, new techniques for model selection and evaluation, data privacy, and model deployment. Additionally, know how you can use the prescriptive features of Apache Airflow to aid your operational journey. Whether you are building using out of the box models (open-source or proprietary), creating new foundation models from scratch, or fine-tuning an existing model, with the structured approaches described you can effectively integrate LLMs into your operations, enhancing efficiency and productivity without causing disruptions in the cloud or on-premises.
Li-Ya Wang
(AWS Solution Architect)
In her talk, Li-Ya Wang will share her experiences being an AWS Solution Architect. She will provide a high-level overview of Amazon S3, its role in global data management and share practical tips on using AWS Intelligent Tiering to reduce costs for teams and services.
Mathew Godfrey
(Customer Solutions Manager)
All-star panel session on level-headed decision making during major incidents.
Paul Le Page
(Solutions Architect)
Paul will share details on the operational culture here at Amazon and explain how we deal with failures – and perhaps more importantly, how we maximise and apply our learnings from them.
Parnab Basak
(Solutions Architect)
Today, all major cloud service providers and 3rd party providers include Apache Airflow as a managed service offering in their portfolios. While these cloud based solutions help with the undifferentiated heavy lifting of environment management, some data teams are also looking to operate self-managed Airflow instances to satisfy specific differentiated capabilities. In this session, we would talk about: Why should you might need to run self managed Airflow The available deployment options (with emphasis on Airflow on Kubernetes) How to deploy Airflow on Kubernetes using automation (Helm Charts & Terraform) Developer experience (sync DAGs using automation) Operator experience (Observability) Owned responsibilities and Tradeoffs A thorough understanding would help you understand the end-to-end perspectives of operating a highly available and scalable self managed Airflow environment to meet your ever growing workflow needs.
Parnab Basak
(Solutions Architect)
Organizations need to effectively manage large volumes of complex, business-critical workloads across multiple applications and platforms. Choosing the right workflow orchestration tool is important as it can help teams effectively automate the configuration, coordination, integration, and data management processes on several applications and systems. Currently there are a lot of tools (both open sourced and proprietary) available for orchestrating tasks and data workflows with automation features. Each of them claim to focus on ensuring a centralized, repeatable, reproducible, and efficient workflows coordination. Choosing one among them is an arduous task as it requires an in-depth understanding of the capabilities that these tools have to offer that translate to your specific engineering needs. Apache Airflow which is a powerful and widely-used open-source workflow management system (WMS) designed to programmatically author, schedule, orchestrate, and monitor data pipelines and workflows. In this talk, understand how Apache Airflow compares with other popular orchestration tools in-terms of architecture, scalability, management, observability, automation, native features, cost, available integrations and more. Get a head-to-head comparison of what’s possible as we dissect capabilities of the tools against the other. This comparative analysis will help you in your decision making process, whether you are planning to migrate an existing system or evaluating for your first enterprise orchestration platform.
Suman Debnath
(Principal AI/ML Advocate)