Migrating Complex SAS Processes to Databricks - Case Study
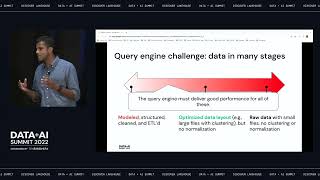
Many federal agencies use SAS software for critical operational data processes. While SAS has historically been a leader in analytics, it has often been used by data analysts for ETL purposes as well. However, modern data science demands on ever-increasing volumes and types of data require a shift to modern, cloud architectures and data management tools and paradigms for ETL/ELT. In this presentation, we will provide a case study at Centers for Medicare and Medicaid Services (CMS) detailing the approach and results of migrating a large, complex legacy SAS process to modern, open-source/open-standard technology - Spark SQL & Databricks – to produce results ~75% faster without reliance on proprietary constructs of the SAS language, with more scalability, and in a manner that can more easily ingest old rules and better govern the inclusion of new rules and data definitions. Significant technical and business benefits derived from this modernization effort are described in this session.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/