Data breach is a concern for any data collection company including Northwestern mutual. Every measure is taken to avoid the identity theft and fraud for our customers; however they are still not sufficient if the security around it is not updated periodically. A multiple layer of encryption is the most common approach utilized to avoid breaches however unauthorized internal access to this sensitive data still poses a threat
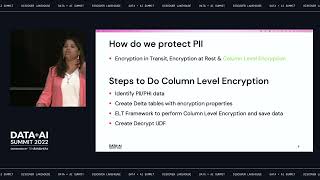
This presentation will walk you following steps: - Design to build encryption at column level - How to protect PII data that is used as key for joins - Ability for authorized users to decrypt data at run time - Ability to rotate the encryption keys if needed
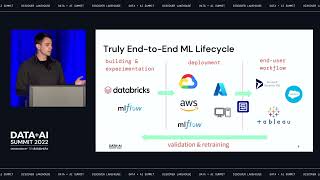
At Northwestern Mutual, a combination of Fernet, AES encryption libraries, user-defined functions (UDFs), and Databricks secrets, were utilized to develop a process to encrypt PII information. Access was only provided to those with a business need to decrypt it, this helps avoids the internal threat. This is also done without data duplication or metadata (view/tables) duplication. Our goal is to help you understand on how you can build a secure data lake for your organization which can eliminate threats of data breach internally and externally. Associated blog: https://databricks.com/blog/2020/11/20/enforcing-column-level-encryption-and-avoiding-data-duplication-with-pii.html
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/