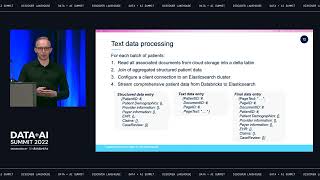
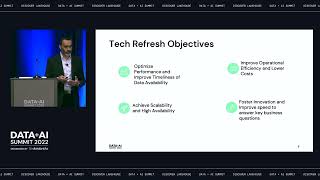
Many organizations rely on complex cloud data architectures that create silos between applications, users and data. This fragmentation makes it difficult to access accurate, up-to-date information for analytics, often resulting in the use of outdated data. Enter the lakehouse, a modern data architecture that unifies data, AI, and analytics in a single location.
This session explores why the lakehouse is the best data warehouse, featuring success stories, use cases and best practices from industry experts. You'll discover how to unify and govern business-critical data at scale to build a curated data lake for data warehousing, SQL and BI. Additionally, you'll learn how Databricks SQL can help lower costs and get started in seconds with on-demand, elastic SQL serverless warehouses, and how to empower analytics engineers and analysts to quickly find and share new insights using their preferred BI and SQL tools such as Fivetran, dbt, Tableau, or Power BI.
Talk by: Miranda Luna and Cyrielle Simeone
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc