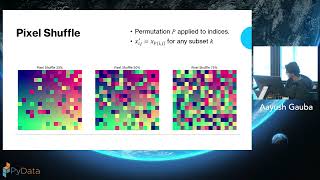
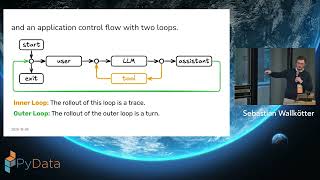
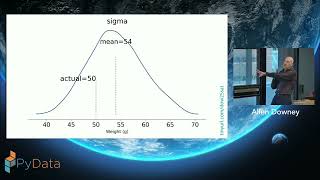
The Column's the limit: interactive exploration of larger than memory data sets in a notebook with Polars and Buckaroo
Notebooks struggle when data vastly exceeds RAM: pagination hacks, fragile sampling, and surprise OOMs. Buckaroo is a modern data table for notebooks built to quickly make sense of dataframes by providing search, summary stats, and scrolling with every view. This talk reviews how Buckaroo uses out‑of‑core design patterns, viewport streaming, lazy Polars pipelines, batched background stats, and a series cache to make interactive exploration fast and reliable on commodity laptops. We’ll walk through the lifecycle of opening a large Parquet/CSV file: detecting formats, avoiding full materialization, fetching only requested row/column ranges, and throttling UI updates for smoothness. We’ll show how column‑level hashing (via a lightweight Rust extension) enables stable, cache keys so warm loads render the first viewport and stats in under a second. CSV specifics and a practical CSV→Parquet streaming path round out the approach. The ideas are tool‑agnostic and reproducible with the open‑source PyData stack; Buckaroo serves as a concrete reference implementation. You’ll leave with guidelines and snippets to bring these patterns to your own workflows.