Break
2025-12-08
Event
Activities tracked
65
Sessions & talks
Showing 51–65 of 65 · Newest first
Learn to build practical LLM agents using LlamaBot and Marimo notebooks. This hands-on tutorial teaches the most important lesson in agent development: start with workflows, not technology.
We'll build a complete back-office automation system through three agents: a receipt processor that extracts data from PDFs, an invoice writer that generates documents, and a coordinator that orchestrates both. This demonstrates the fundamental pattern for agent systems—map your boring workflows first, build focused agents for specific tasks, then compose them so agents can use other agents as tools.
By the end, you'll understand how to identify workflows worth automating, build agents with decision-making loops, compose agents into larger systems, and integrate them into your own work. You'll leave with working code and confidence to automate repetitive tasks.
Prerequisites: Intermediate Python, familiarity with APIs, basic LLM understanding. Participants should have Ollama and models installed beforehand (setup instructions provided).
Materials: GitHub repository with Marimo notebooks. Setup uses Pixi for dependency management.

Unlocking the full potential of AI starts with your data, but real-world documents come in countless formats and levels of complexity. This session will give you hands-on experience with Docling, an open-source Python library designed to convert complex documents into AI-ready formats. Learn how Docling simplifies document processing, enabling you to efficiently harness all your data for downstream AI and analytics applications.
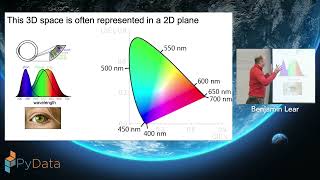
The default color space for computers includes over 16 million colors—an embarrassment of riches that is also a potential quagmire to anyone considering how to best choose colors for visualizations. In this workshop, we will provide a practical framework for working with color. We will start by developing an understanding of color models and color theory, building from these to provide simple but powerful heuristics for color selection that will enable creators of data visualization to enhance the clarity, power, and storytelling of their visualizations. We will conclude with the introduction of tools for working with and selecting color, followed by hands-on activities using these tools. No prior knowledge is needed or assumed, and the only tools you will need is a computer with a web browser and an internet connection.
This tutorial tackles a fundamental challenge in modern AI development: creating a standardized, reusable way for AI agents to interact with the outside world. We will explore the Model Context Protocol (MCP) designed to connect AI agents with external systems providing tools, data, and workflows. This session provides a first-principles understanding of the protocol, by building an MCP server from scratch, attendees will learn the core mechanics of the protocol's data layer: lifecycle management, capability negotiation, and the implementation of server-side "primitives." The goal is to empower attendees to build their own MCP-compliant services, enabling their data and tools to be used by a growing ecosystem of AI applications.
PubMed is a free search interface for biomedical literature, including citations and abstracts from many life science scientific journals. It is maintained by the National Library of Medicine at the NIH. Yet, most users only interact with it through simple keyword searches. In this hands-on tutorial, we will introduce PubMed as a data source for intelligent biomedical research assistants — and build a Health Research AI Agent using modern agentic AI frameworks such as LangChain, LangGraph, and Model Context Protocol (MCP) with minimum hardware requirements and no key tokens. To ensure compatibility, the agent will run in a Docker container which will host all necessary elements.
Participants will learn how to connect language models to structured biomedical knowledge, design context-aware queries, and containerize the entire system using Docker for maximum portability. By the end, attendees will have a working prototype that can read and reason over PubMed abstracts, summarize findings according to a semantic similarity engine, and assist with literature exploration — all running locally on modest hardware.
Expected Audience: Enthusiasts, researchers, and data scientists interested in AI agents, biomedical text mining, or practical LLM integration. Prior Knowledge: Python and Docker familiarity; no biomedical background required. Minimum Hardware Requirements: 8GB RAM (+16GB recommended), 30GB disk space, Docker pre-installed. MacOS, Windows, Linux. Key Takeaway: How to build a lightweight, reproducible research agent that combines open biomedical data with modern agentic AI frameworks.
We'll explore best practices for writing CUDA kernels using Python, empowering developers to harness the full potential of GPU acceleration. Gain a clear understanding of the structure and functionality of CUDA kernels, learning how to effectively implement them within Python applications.

In this hands-on tutorial, you'll go from a blank notebook to a fully orchestrated data pipeline built entirely in Python, all in under 90 minutes. You'll learn how to design and deploy end-to-end data pipelines using familiar notebook environments, using Python for your data loading, data transformations, and insights delivery.
We'll dive into the Ingestion-Tranformation-Delivery (ITD) framework for building data pipelines: ingest raw data from cloud object storage, transform the data using Python DataFrames, and deliver insights via a Streamlit application.
Basic familiarity with Python (and/or SQL) is helpful, but not required. By the end of the session, you'll understand practical data engineering patterns and leave with reusable code templates to help you build, orchestrate, and deploy data pipelines from notebook environments.

Recommender systems power everything from e-commerce to media streaming, but most pipelines still rely on collaborative filtering or neural models that focus narrowly on user–item interactions. Large language models (LLMs), by contrast, excel at reasoning across unstructured text, contextual information, and explanations. This tutorial bridges the two worlds. Participants will build a hybrid recommender system that uses structured embeddings for retrieval and integrates an LLM layer for personalization and natural-language explanations. We’ll also discuss practical engineering constraints: scaling, latency, caching, distillation/quantization, and fairness. By the end, attendees will leave with a working hybrid recommender they can extend for their own data, along with a playbook for when and how to bring LLMs into recommender workflows responsibly.