LLMOps in Practice: Building Secure, Governed Pipelines for Large Language Models
As organizations move from prototyping LLMs to deploying them in production, the biggest challenges are no longer about model accuracy - they’re about trust, security, and control. How do we monitor model behavior, prevent prompt injection, track drift, and enforce governance across environments?
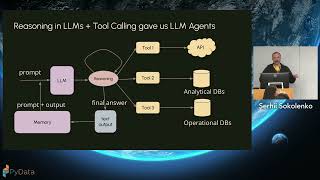
This talk presents a real-world view of how to design secure and governed LLM pipelines, grounded in open-source tooling and reproducible architectures. We’ll discuss how multi-environment setups (sandbox, runner, production) can isolate experimentation from deployment, how to detect drift and hallucination using observability metrics, and how to safeguard against prompt injection, data leakage, and bias propagation.
Attendees will gain insight into how tools like MLflow, Ray, and TensorFlow Data Validation can be combined for ** version tracking, monitoring, and auditability**, without turning your workflow into a black box. By the end of the session, you’ll walk away with a practical roadmap on what makes an LLMOps stack resilient: reproducibility by design, continuous evaluation, and responsible governance across the LLM lifecycle.