with
Barry McCardel
(Hex)
,
Colin Zima
(Omni)
,
Jordan Tigani
(MotherDuck)
,
Tristan Handy
(dbt Labs)
,
Barr Moses
(Monte Carlo)
 talk-data.com
talk-data.com
B
Speaker
Barr Moses
18
talks
CEO & Co-Founder
Monte Carlo
Barr Moses is the CEO and Co-founder of Monte Carlo, the leader in the data observability category. The company is backed by top Silicon Valley investors including Accel, GGV, Redpoint, ICONIQ Growth, Salesforce Ventures, IVP, and more. Monte Carlo works with major customers such as Cisco, American Airlines, and NASDAQ to drive positive business outcomes through reliable data and AI. Moses is recognized for building and leading a data observability platform at the forefront of data reliability and AI-enabled decision-making.
Bio from: dbt Coalesce 2023
Frequent Collaborators
Filter by Event / Source
Data Engineering Podcast
3
DataFramed
3
The Analytics Power Hour
2
DataTalks.Club
1
Making Data Simple
1
Shift Left Data Conference 2025
1
DATA MINER Big Data Europe Conference 2020
1
Databricks DATA + AI Summit 2023
1
dbt Coalesce 2023
1
Data + AI Summit 2025
1
Modern Data Stack Conference 2023
1
Small Data SF 2025
1
Airflow Summit 2022
1
Talks & appearances
18 activities · Newest first

Agentic AI is the next evolution in artificial intelligence, with the potential to revolutionize the industry. However, its potential is matched only by its risk: without high-quality, trustworthy data, agentic AI can be exponentially dangerous. Join Barr Moses, CEO and Co-Founder of Monte Carlo, to explore how to leverage Databricks' powerful platform to ensure your agentic AI initiatives are underpinned by reliable, high-quality data. Barr will share: How data quality impacts agentic AI performance at every stage of the pipeline Strategies for implementing data observability to detect and resolve data issues in real-time Best practices for building robust, error-resilient agentic AI models on Databricks. Real-world examples of businesses harnessing Databricks' scalability and Monte Carlo’s observability to drive trustworthy AI outcomes Learn how your organization can deliver more reliable agentic AI and turn the promise of autonomous intelligence into a strategic advantage.Audio for this session is delivered in the conference mobile app, you must bring your own headphones to listen.

Panel: Shift Left Across the Data Lifecycle—Data Contracts, Transformations, Observability, and C...
with
Chad Sanderson
(Gable.ai)
,
Tristan Handy
(dbt Labs)
,
Barr Moses
(Monte Carlo)
,
Prukalpa Sankar
(Atlan)
Panel: Shift Left Across the Data Lifecycle—Data Contracts, Transformations, Observability, and Catalogs | Prukalpa Sankar, Tristan Handy, Barr Moses, Chad Sanderson | Shift Left Data Conference 2025
Join industry-leading CEOs Chad (Data Contracts), Tristan (Data Transformations), Barr (Data Observability), and Prukalpa (Data Catalogs) who are pioneering new approaches to operationalizing data by “Shifting Left.” This engaging panel will explore how embedding rigorous data management practices early in the data lifecycle reduces issues downstream, enhances data reliability, and empowers software engineers with clear visibility into data expectations. Attendees will gain insights into how data contracts define accountability, how effective transformations ensure data usability at scale, how proactive how proactive data and AI observability drives continuous confidence in data quality, and how catalogs enable data discoverability, accelerating innovation and trust across organizations.
with
Val Kroll
,
Julie Hoyer
,
Tim Wilson
(Analytics Power Hour - Columbus (OH)
,
Barr Moses
(Monte Carlo)
,
Moe Kiss
(Canva)
,
Michael Helbling
(Search Discovery)
Every year kicks off with an air of expectation. How much of our Professional Life in 2025 is going to look a lot like 2024? How much will look different, but we have a pretty good idea of what the difference will be? What will surprise us entirely—the unknown unknowns? By definition, that last one is unknowable. But we thought it would be fun to sit down with returning guest Barr Moses from Monte Carlo to see what we could nail down anyway. The result? A pretty wide-ranging discussion about data observability, data completeness vs. data connectedness, structured data vs. unstructured data, and where AI sits from an input and an output and a processing engine. And more. Moe and Tim even briefly saw eye to eye on a thing or two (although maybe that was just a hallucination). For complete show notes, including links to items mentioned in this episode and a transcript of the show, visit the show page.
Generative AI's transformative power underscores the critical need for high-quality data. In this session, Barr Moses, CEO of Monte Carlo Data, Prukalpa Sankar, Cofounder at Atlan, and George Fraser, CEO at Fivetran, discuss the nuances of scaling data quality for generative AI applications, highlighting the unique challenges and considerations that come into play. Throughout the session, they share best practices for data and AI leaders to navigate these challenges, ensuring that governance remains a focal point even amid the AI hype cycle. Links Mentioned in the Show: Rewatch Session from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile app Empower your business with world-class data and AI skills with DataCamp for business
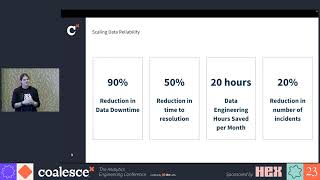
TOCA Football, the largest operator of indoor soccer centers in North America, leverages accurate data to power analytics for over 30 training centers, providing everything from operational insights for executives to ball-by-ball analysis.
In 2020, the team adopted a cloud-native data stack with dbt to scale analytics enablement for the go-to-market org, including the company’s finance, strategy, operations, and marketing teams. By 2022, their lean team of four was struggling to gain visibility into the health and performance of their dbt models. So, what was the TOCA team to do? Two words: data observability.
In this talk, Sam Cvetkovski, Director, Data & Analytics discusses how TOCA built their larger data observability strategy to reduce model bloat, increase data accuracy, and boost stakeholder satisfaction with their team’s data products. She shares her biggest “aha!” moments, key challenges, and best practices for teams getting started on their dbt reliability journeys.
Speakers: Sam Cvetkovski, Director, Data & Analytics, TOCA Football; Barr Moses, Co-Founder & CEO, Monte Carlo
Register for Coalesce at https://coalesce.getdbt.com
Summary
As businesses increasingly invest in technology and talent focused on data engineering and analytics, they want to know whether they are benefiting. So how do you calculate the return on investment for data? In this episode Barr Moses and Anna Filippova explore that question and provide useful exercises to start answering that in your company.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack Your host is Tobias Macey and today I'm interviewing Barr Moses and Anna Filippova about how and whether to measure the ROI of your data team
Interview
Introduction How did you get involved in the area of data management? What are the typical motivations for measuring and tracking the ROI for a data team?
Who is responsible for collecting that information? How is that information used and by whom?
What are some of the downsides/risks of tracking this metric? (law of unintended consequences) What are the inputs to the number that constitutes the "investment"? infrastructure, payroll of employees on team, time spent working with other teams? What are the aspects of data work and its impact on the business that complicate a calculation of the "return" that is generated? How should teams think about measuring data team ROI? What are some concrete ROI metrics data teams can use?
What level of detail is useful? What dimensions should be used for segmenting the calculations?
How can visibility into this ROI metric be best used to inform the priorities and project scopes of the team? With so many tools in the modern data stack today, what is the role of technology in helping drive or measure this impact? How do your respective solutions, Monte Carlo and dbt, help teams measure and scale data value? With generative AI on the upswing of the hype cycle, what are the impacts that you see it having on data teams?
What are the unrealistic expectations that it will produce? How can it speed up time to delivery?
What are the most interesting, innovative, or unexpected ways that you have seen data team ROI calculated and/or used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on measuring the ROI of data teams? When is measuring ROI the wrong choice?
Contact Info
Barr
Anna
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Monte Carlo
Podcast Episode
dbt
Podcast Episode
JetBlue Snowflake Con Presentation Generative AI Large Language Models
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Rudderstack: 
Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guessw
with
Barr Moses
(Monte Carlo)
,
Kevin Petrie
(Eckerson Group)
,
Sarah Catanzaro
(Amplify Partners)
,
Benn Stancil
(Mode)
,
George Fraser
(Fivetran)
As organizations of all sizes continuously look to drive value out of data, the modern data stack has emerged as a clear solution for getting insights into the hands of the organization. With the rapid pace of innovation not slowing down, the tools within the modern data stack have enabled data teams to drive faster insights, collaborate at scale, and democratize data knowledge. However, are tools just enough to drive business value with data? In the first of our four RADAR 2023 sessions, we look at the key drivers of value within the modern data stack through the minds of Yali Sassoon and Barr Moses. Yali Sassoon is the Co-Founder and Chief Strategy Officer at Snowplow Analytics, a behavioral data platform that empowers data teams to solve complex data challenges. At Snowplow, Yali gets to combine his love of building things with his fascination of the ways in which people use data to reason. Barr Moses is CEO & Co-Founder of Monte Carlo. Previously, she was VP Customer Operations at customer success company Gainsight, where she helped scale the company 10x in revenue and, among other functions, built the data/analytics team. Listen in as Yali and Barr outline how data leaders can drive value creation with data in 2023.
Summary Data observability is a product category that has seen massive growth and adoption in recent years. Monte Carlo is in the vanguard of companies who have been enabling data teams to observe and understand their complex data systems. In this episode founders Barr Moses and Lior Gavish rejoin the show to reflect on the evolution and adoption of data observability technologies and the capabilities that are being introduced as the broader ecosystem adopts the practices.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. The only thing worse than having bad data is not knowing that you have it. With Bigeye’s data observability platform, if there is an issue with your data or data pipelines you’ll know right away and can get it fixed before the business is impacted. Bigeye let’s data teams measure, improve, and communicate the quality of your data to company stakeholders. With complete API access, a user-friendly interface, and automated yet flexible alerting, you’ve got everything you need to establish and maintain trust in your data. Go to dataengineeringpodcast.com/bigeye today to sign up and start trusting your analyses. Your host is Tobias Macey and today I’m interviewing Barr Moses and Lior Gavish about the state of the market for data observability and their own work at Monte Carlo
Interview
Introduction How did you get involved in the area of data management? Can you give the elevator pitch for Monte Carlo?
What are the notable changes in the Monte Carlo product and business since our last conversation in October 2020?
You were one of the early entrants in the market of data quality/data observability products. In your work to gain visibility and traction you invested substantially in content creation (blog posts, presentations, round table conversations, etc.). How would you summarize the focus of your initial efforts? Why do you think data observability has really taken off? A few years ago, the category barely existed – what’s changed? There’s a larger debate within

"Why did our dashboard break?" "What happened to my data?" "Why is this column missing?" If you've been on the receiving end of these messages (and many others!) from downstream stakeholders, you're not alone. Data engineering teams spend 40 percent or more of their time tackling data downtime, or periods of time when data is missing, erroneous, or otherwise inaccurate, and as data systems become increasingly complex and distributed, this number will only increase. To address this problem, data observability is becoming an increasingly important part of the cloud data stack, helping engineers and analysts reduce time to detection and resolution for data incidents caused by faulty data, code, and operational environments. But what does data observability actually look like in practice? During this presentation, Barr Moses, CEO and co-founder of Monte Carlo, will present on how some of today's best data leaders implement observability across their data lake ecosystem and share best practices for data teams seeking to achieve end-to-end visibility into their data at scale. Topics addressed will include: building automated lineage for Apache Spark, applying data reliability workflows, and extending beyond testing and monitoring to solve for unknown unknowns in your data pipelines.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
Broken data is costly, time-consuming, and nowadays, an all-too-common reality for even the most advanced data teams. In this talk, I’ll introduce this problem, called “data downtime” — periods of time when data is partial, erroneous, missing or otherwise inaccurate — and discuss how to eliminate it in your data ecosystem with end-to-end data observability. Drawing corollaries to application observability in software engineering, data observability is a critical component of the modern DataOps workflow and the key to ensuring data trust at scale. I’ll share why data observability matters when it comes to building a better data quality strategy and highlight tactics you can use to address it today.
Send us a text Welcome Barr Moses CEO & Co - Founder of Monte Carlo, a data reliability company. We talk detection, resolution, prevention and the 5 pillars of data observability. Great dialog. Show Notes 03:53 : Zero defect data 06:02 : Customer success learnings 10:42 : Delivering value with data 14:00 : Monte Carlo, the name 18:20 : Data observability 23:38 : Detection, resolution, prevention 31:12 : Duplicate data brings Netflix down 34:22 : 5 pillars of data observability 36:22 : "Building data like a product" 39:37 : Monte Carlo's differentiation Find Barr : linkedin.com/in/barrmoses Website : https://www.montecarlodata.com/ Want to be featured as a guest on Making Data Simple? Reach out to us at [email protected] and tell us why you should be next. The Making Data Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, where we explore trending technologies, business innovation, and leadership ... while keeping it simple & fun. Want to be featured as a guest on Making Data Simple? Reach out to us at [email protected] and tell us why you should be next. The Making Data Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, where we explore trending technologies, business innovation, and leadership ... while keeping it simple & fun.
In this episode of DataFramed, Adel speaks with Barr Moses, CEO, and co-founder of Monte Carlo on the importance of data quality and how data observability creates trust in data throughout the organization.
Throughout the episode, Barr talks about her background, the state of data-driven organizations and what it means to be data-driven, the data maturity of organizations, the importance of data quality, what data observability is, and why we’ll hear about it more often in the future. She also covers the state of data infrastructure, data meshes, and more.
Relevant links from the interview:
Connect with Barr on LinkedInLearn more about data meshesCheck out the Monte Carlo blogDataCamp's Guide to Organizational Data Maturity
We covered:
Barr’s background Market gaps in data reliability Observability in engineering Data downtime Data quality problems and the five pillars of data observability Example: job failing because of a schema change Three pillars of observability (good pipelines and bad data) Observability vs monitoring Finding the root cause Who is accountable for data quality? (the RACI framework) Service level agreements Inferring the SLAs from the historical data Implementing data observability Data downtime maturity curve Monte carlo: data observability solution Open source tools Test-driven development for data Is data observability cloud agnostic? Centralizing data observability Detecting downstream and upstream data usage Getting bad data vs getting unusual data
Links:
Learn more about Monte Carlo: https://www.montecarlodata.com/ The Data Engineer's Guide to Root Cause Analysis: https://www.montecarlodata.com/the-data-engineers-guide-to-root-cause-analysis/ Why You Need to Set SLAs for Your Data Pipelines: https://www.montecarlodata.com/how-to-make-your-data-pipelines-more-reliable-with-slas/ Data Observability: The Next Frontier of Data Engineering: https://www.montecarlodata.com/data-observability-the-next-frontier-of-data-engineering/ To get in touch with Barr, ping her in the DataTalks.Club group or use [email protected]
Join DataTalks.Club: https://datatalks.club/slack.html

Big Data Europe Onsite and online on 22-25 November in 2022 Learn more about the conference: https://bit.ly/3BlUk9q
Join our next Big Data Europe conference on 22-25 November in 2022 where you will be able to learn from global experts giving technical talks and hand-on workshops in the fields of Big Data, High Load, Data Science, Machine Learning and AI. This time, the conference will be held in a hybrid setting allowing you to attend workshops and listen to expert talks on-site or online.
with
Val Kroll
,
Julie Hoyer
,
Tim Wilson
(Analytics Power Hour - Columbus (OH)
,
Barr Moses
(Monte Carlo)
,
Moe Kiss
(Canva)
,
Michael Helbling
(Search Discovery)
You know that sinking feeling: the automated report went out first thing Monday morning, and your Slack messages have been blowing up ever since because revenue flatlined on Saturday afternoon! You frantically start digging in (spilling your coffee in the process!) while you're torn between hoping that it's "just a data issue" (which would be good for the company but a black mark on the data team) and that it's a "real issue with the site" (not good for the business, but at least your report was accurate!). Okay. So, maybe you've never had that exact scenario, but we've all dealt with data breakages occurring in various unexpected nooks and crannies of our data ecosystem. It can be daunting to make a business case to invest in monitoring and observing all the various data pipes and tables to proactively identify data issues. But, as our data gets broader and deeper and more business-critical, can we afford not to? On this episode, we were joined by Barr Moses, co-founder and CEO of Monte Carlo to chat about practical strategies and frameworks for monitoring data and reducing data downtime! For complete show notes, including links to items mentioned in this episode and a transcript of the show, visit the show page.
Summary In order for analytics and machine learning projects to be useful, they require a high degree of data quality. To ensure that your pipelines are healthy you need a way to make them observable. In this episode Barr Moses and Lior Gavish, co-founders of Monte Carlo, share the leading causes of what they refer to as data downtime and how it manifests. They also discuss methods for gaining visibility into the flow of data through your infrastructure, how to diagnose and prevent potential problems, and what they are building at Monte Carlo to help you maintain your data’s uptime.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management What are the pieces of advice that you wish you had received early in your career of data engineering? If you hand a book to a new data engineer, what wisdom would you add to it? I’m working with O’Reilly on a project to collect the 97 things that every data engineer should know, and I need your help. Go to dataengineeringpodcast.com/97things to add your voice and share your hard-earned expertise. When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their managed Kubernetes platform it’s now even easier to deploy and scale your workflows, or try out the latest Helm charts from tools like Pulsar and Pachyderm. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform. Go to dataengineeringpodcast.com/linode today and get a $60 credit to try out a Kubernetes cluster of your own. And don’t forget to thank them for their continued support of this show! Are you bogged down by having to manually manage data access controls, repeatedly move and copy data, and create audit reports to prove compliance? How much time could you save if those tasks were automated across your cloud platforms? Immuta is an automated data governance solution that enables safe and easy data analytics in the cloud. Our comprehensive data-level security, auditing and de-identification features eliminate the need for time-consuming manual processes and our focus on data and compliance team collaboration empowers you to deliver quick and valuable data analytics on the most sensitive data to unlock the full potential of your cloud data platforms. Learn how we streamline and accelerate manual processes to help you derive real results from your data at dataengineeringpodcast.com/immuta. Today’s episode of the Data Engineering Podcast is sponsored by Datadog, a SaaS-based monitoring and analytics platform for cloud-scale infrastructure, applications, logs, and more. Datadog uses machine-learning based algorithms to detect errors and anomalies across your entire stack—which reduces the time it takes to detect and address outages and helps promote collaboration between Data Engineering, Operations, and the rest of the company. Go to dataengineeringpodcast.com/datadog today to start your free 14 day trial. If you start a trial and install Datadog’s agent, Datadog will send you a free T-shirt. You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern data platforms. For more opportunities to stay up to date, gain new skills, and learn from your peers there are a growing number of virtual events that you can attend from the comfort and safety of your home. Go to dataengineeringpodcast.com/conferences to check out the upcoming events being offered by our partners and get registered today! Your host is Tobias Macey and today I’m interviewing Barr Moses and Lior Gavish about observability for your data pipelines and how they are addressing it at Monte Carlo.
Interview
Introduction How did you get involved in the area of data management? H