The AI landscape is evolving at breakneck speed, with new capabilities emerging quarterly that redefine what's possible. For professionals across industries, this creates a constant need to reassess workflows and skills. How do you stay relevant when the technology keeps leapfrogging itself? What happens to traditional roles when AI can increasingly handle complex tasks that once required specialized expertise? With product-market fit becoming a moving target and new positions like forward-deployed engineers emerging, understanding how to navigate this shifting terrain is crucial. The winners won't just be those who adopt AI—but those who can continuously adapt as it evolves. Tomasz Tunguz is a General Partner at Theory Ventures, a $235m early-stage venture capital firm. He blogs at tomtunguz.com & co-authored Winning with Data. He has worked or works with Looker, Kustomer, Monte Carlo, Dremio, Omni, Hex, Spot, Arbitrum, Sui & many others. He was previously the product manager for Google's social media monetization team, including the Google-MySpace partnership, and managed the launches of AdSense into six new markets in Europe and Asia. Before Google, Tunguz developed systems for the Department of Homeland Security at Appian Corporation. In the episode, Richie and Tom explore the rapid investment in AI, the evolution of AI models like Gemini 3, the role of AI agents in productivity, the shifting job market, the impact of AI on customer success and product management, and much more. Links Mentioned in the Show: Theory VenturesConnect with TomTom’s BlogGavin Baker on MediumAI-Native Course: Intro to AI for WorkRelated Episode: Data & AI Trends in 2024, with Tom Tunguz, General Partner at Theory VenturesRewatch RADAR AI New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
 talk-data.com
talk-data.com
Topic
Monte Carlo
106
tagged
Activity Trend
Top Events
Data quality and AI reliability are two sides of the same coin in today's technology landscape. Organizations rushing to implement AI solutions often discover that their underlying data infrastructure isn't prepared for these new demands. But what specific data quality controls are needed to support successful AI implementations? How do you monitor unstructured data that feeds into your AI systems? When hallucinations occur, is it really the model at fault, or is your data the true culprit? Understanding the relationship between data quality and AI performance is becoming essential knowledge for professionals looking to build trustworthy AI systems. Shane Murray is a seasoned data and analytics executive with extensive experience leading digital transformation and data strategy across global media and technology organizations. He currently serves as Senior Vice President of Digital Platform Analytics at Versant Media, where he oversees the development and optimization of analytics capabilities that drive audience engagement and business growth. In addition to his corporate leadership role, he is a founding member of InvestInData, an angel investor collective of data leaders supporting early-stage startups advancing innovation in data and AI. Prior to joining Versant Media, Shane spent over three years at Monte Carlo, where he helped shape AI product strategy and customer success initiatives as Field CTO. Earlier, he spent nearly a decade at The New York Times, culminating as SVP of Data & Insights, where he was instrumental in scaling the company’s data platforms and analytics functions during its digital transformation. His earlier career includes senior analytics roles at Accenture Interactive, Memetrics, and Woolcott Research. Based in New York, Shane continues to be an active voice in the data community, blending strategic vision with deep technical expertise to advance the role of data in modern business. In the episode, Richie and Shane explore AI disasters and success stories, the concept of being AI-ready, essential roles and skills for AI projects, data quality's impact on AI, and much more. Links Mentioned in the Show: Versant MediaConnect with ShaneCourse: Responsible AI PracticesRelated Episode: Scaling Data Quality in the Age of Generative AI with Barr Moses, CEO of Monte Carlo Data, Prukalpa Sankar, Cofounder at Atlan, and George Fraser, CEO at FivetranRewatch RADAR AI New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
When Virgin Media and O2 merged, they faced the challenge of unifying thousands of pipelines and platforms while keeping 25 million customers connected. Victor Rivero, Head of Data Governance & Quality, shares how his team is transforming his data estate into a trusted source of truth by embedding Monte Carlo’s Data + AI Observability across BigQuery, Atlan, dbt, and Tableau. Learn how they've begun their journey to cut data downtime, enforced reliability dimensions, and measured success while creating a scalable blueprint for enterprise observability.
How do you deliver reliable data across dozens of countries, diverse tech stacks, and constantly evolving use cases? In this session, Vinicio Oliviera, Senior Data Platform Manager at Delivery Hero, shares how his team ensures trust in data at scale. From real-time sales streams to AI-driven vendor insights, he’ll show how Delivery Hero uses Monte Carlo’s monitoring-as-code to unify reliability across regions, balance central standards with local autonomy, and keep data powering decisions around the globe.
As the pioneers of the low-code market since 2001, enterprise software delivery solution OutSystems has evolved rapidly alongside the changing landscape of data. With a global presence and a vast community of over 750,000 members, OutSystems continues to leverage innovative tools, including data observability and generative AI, to help their customers succeed.
In this session, Pedro Sá Martins, Head of Data Engineering, will share the evolution of OutSystems’ data landscape, including how OutSystems has partnered with Snowflake, Fivetran and Monte Carlo to address their modern data challenges. He’ll share best practices for implementing scalable data quality programs to drive innovative technologies, as well as what’s on the data horizon for the OutSystems team.

Put statistics into practice with Python! Data-driven decisions rely on statistics. Statistics Every Programmer Needs introduces the statistical and quantitative methods that will help you go beyond “gut feeling” for tasks like predicting stock prices or assessing quality control, with examples using the rich tools of the Python ecosystem. Statistics Every Programmer Needs will teach you how to: Apply foundational and advanced statistical techniques Build predictive models and simulations Optimize decisions under constraints Interpret and validate results with statistical rigor Implement quantitative methods using Python In this hands-on guide, stats expert Gary Sutton blends the theory behind these statistical techniques with practical Python-based applications, offering structured, reproducible, and defensible methods for tackling complex decisions. Well-annotated and reusable Python code listings illustrate each method, with examples you can follow to practice your new skills. About the Technology Whether you’re analyzing application performance metrics, creating relevant dashboards and reports, or immersing yourself in a numbers-heavy coding project, every programmer needs to know how to turn raw data into actionable insight. Statistics and quantitative analysis are the essential tools every programmer needs to clarify uncertainty, optimize outcomes, and make informed choices. About the Book Statistics Every Programmer Needs teaches you how to apply statistics to the everyday problems you’ll face as a software developer. Each chapter is a new tutorial. You’ll predict ultramarathon times using linear regression, forecast stock prices with time series models, analyze system reliability using Markov chains, and much more. The book emphasizes a balance between theory and hands-on Python implementation, with annotated code and real-world examples to ensure practical understanding and adaptability across industries. What's Inside Probability basics and distributions Random variables Regression Decision trees and random forests Time series analysis Linear programming Monte Carlo and Markov methods and much more About the Reader Examples are in Python. About the Author Gary Sutton is a business intelligence and analytics leader and the author of Statistics Slam Dunk: Statistical analysis with R on real NBA data. Quotes A well-organized tour of the statistical, machine learning and optimization tools every data science programmer needs. - Peter Bruce, Author of Statistics for Data Science and Analytics Turns statistics from a stumbling block into a superpower. Clear, relevant, and written with a coder’s mindset! - Mahima Bansod, LogicMonitor Essential! Stats and modeling with an emphasis on real-world system design. - Anupam Samanta, Google A great blend of theory and practice. - Ariel Andres, Scotia Global Asset Management
Shane Murray (Field CTO Monte Carlo, Former Head of Data NY Times) joins me to chat about the impact of AI on data teams and business strategies, data observability on unstructured data, and more.
OpenMC is an open source, community-developed, Monte Carlo tool for neutron transport simulations, featuring a depletion module for fuel burnup calculations in nuclear reactors and a Python API. Depletion calculations can be expensive as they require solving the neutron transport and bateman equations in each timestep to update the neutron flux and material composition, respectively. Material properties such as temperature and density govern material cross sections, which in turn govern reaction rates. The reaction rates can effect the neutron population. In a scenario where there is no significant change in the material properties or composition, the transport simulation may only need to be run once; the same cross sections are used for the entire depletion calculation. We recently extended the depletion module in OpenMC to enable transport-independent depletion using multigroup cross sections and fluxes. This talk will focus on the technical details of this feature, its validation, and briefly touch on areas where the feature has been used. Two recent use cases will be highlighted. The first use case calculates shutdown dose rates for fusion power applications, and the second performs depletion for fission reactor fuel cycle modeling.

American Airlines, one of the largest airlines in the world, processes a tremendous amount of data every single minute. With a data estate of this scale, accountability for the data goes beyond the data team; the business organization has to be equally invested in championing the quality, reliability, and governance of data. In this session, Andrew Machen, Senior Manager, Data Engineering at American Airlines will share how his team maximizes resources to deliver reliable data at scale. He'll also outline his strategy for aligning business leadership with an investment in data reliability, and how leveraging Monte Carlo's data + AI observability platform enabled them to reduce time spent resolving data reliability issues from 10 weeks to 2 days, saving millions of dollars and driving valuable trust in the data.

Agentic AI is the next evolution in artificial intelligence, with the potential to revolutionize the industry. However, its potential is matched only by its risk: without high-quality, trustworthy data, agentic AI can be exponentially dangerous. Join Barr Moses, CEO and Co-Founder of Monte Carlo, to explore how to leverage Databricks' powerful platform to ensure your agentic AI initiatives are underpinned by reliable, high-quality data. Barr will share: How data quality impacts agentic AI performance at every stage of the pipeline Strategies for implementing data observability to detect and resolve data issues in real-time Best practices for building robust, error-resilient agentic AI models on Databricks. Real-world examples of businesses harnessing Databricks' scalability and Monte Carlo’s observability to drive trustworthy AI outcomes Learn how your organization can deliver more reliable agentic AI and turn the promise of autonomous intelligence into a strategic advantage.Audio for this session is delivered in the conference mobile app, you must bring your own headphones to listen.

Your model is trained. Your pilot is live. Your data looks AI-ready. But for most teams, the toughest part of building successful AI starts after deployment. In this talk, Shane Murray and Ethan Post share lessons from the development of Monte Carlo’s Troubleshooting Agent – an AI assistant that helps users diagnose and fix data issues in production. They’ll unpack what it really takes to build and operate trustworthy AI systems in the real world, including: The Illusion of Done – Why deployment is just the beginning, and what breaks in production; Lessons from the Field – A behind-the-scenes look at the architecture, integration, and user experience of Monte Carlo’s agent; Operationalizing Reliability – How to evaluate AI performance, build the right team, and close the loop between users and model. Whether you're scaling RAG pipelines or running LLMs in production, you’ll leave with a playbook for building data and AI systems you—and your users—can trust.

Learn how machine learning algorithms work from the ground up so you can effectively troubleshoot your models and improve their performance. Fully understanding how machine learning algorithms function is essential for any serious ML engineer. In Machine Learning Algorithms in Depth you’ll explore practical implementations of dozens of ML algorithms including: Monte Carlo Stock Price Simulation Image Denoising using Mean-Field Variational Inference EM algorithm for Hidden Markov Models Imbalanced Learning, Active Learning and Ensemble Learning Bayesian Optimization for Hyperparameter Tuning Dirichlet Process K-Means for Clustering Applications Stock Clusters based on Inverse Covariance Estimation Energy Minimization using Simulated Annealing Image Search based on ResNet Convolutional Neural Network Anomaly Detection in Time-Series using Variational Autoencoders Machine Learning Algorithms in Depth dives into the design and underlying principles of some of the most exciting machine learning (ML) algorithms in the world today. With a particular emphasis on probabilistic algorithms, you’ll learn the fundamentals of Bayesian inference and deep learning. You’ll also explore the core data structures and algorithmic paradigms for machine learning. Each algorithm is fully explored with both math and practical implementations so you can see how they work and how they’re put into action. About the Technology Learn how machine learning algorithms work from the ground up so you can effectively troubleshoot your models and improve their performance. This book guides you from the core mathematical foundations of the most important ML algorithms to their Python implementations, with a particular focus on probability-based methods. About the Book Machine Learning Algorithms in Depth dissects and explains dozens of algorithms across a variety of applications, including finance, computer vision, and NLP. Each algorithm is mathematically derived, followed by its hands-on Python implementation along with insightful code annotations and informative graphics. You’ll especially appreciate author Vadim Smolyakov’s clear interpretations of Bayesian algorithms for Monte Carlo and Markov models. What's Inside Monte Carlo stock price simulation EM algorithm for hidden Markov models Imbalanced learning, active learning, and ensemble learning Bayesian optimization for hyperparameter tuning Anomaly detection in time-series About the Reader For machine learning practitioners familiar with linear algebra, probability, and basic calculus. About the Author Vadim Smolyakov is a data scientist in the Enterprise & Security DI R&D team at Microsoft. Quotes I love this book! It shows you how to implement common ML algorithms in plain Python with only the essential libraries, so you can see how the computation and math works in practice. - Junpeng Lao, Senior Data Scientist at Google I highly recommend this book. In the era of ChatGPT real knowledge of algorithms is invaluable. - Vatsal Desai, InfoDesk Explains algorithms so well that even a novice can digest it. - Harsh Raval, Zymr
Every year kicks off with an air of expectation. How much of our Professional Life in 2025 is going to look a lot like 2024? How much will look different, but we have a pretty good idea of what the difference will be? What will surprise us entirely—the unknown unknowns? By definition, that last one is unknowable. But we thought it would be fun to sit down with returning guest Barr Moses from Monte Carlo to see what we could nail down anyway. The result? A pretty wide-ranging discussion about data observability, data completeness vs. data connectedness, structured data vs. unstructured data, and where AI sits from an input and an output and a processing engine. And more. Moe and Tim even briefly saw eye to eye on a thing or two (although maybe that was just a hallucination). For complete show notes, including links to items mentioned in this episode and a transcript of the show, visit the show page.
As we look back at 2024, we're highlighting some of our favourite episodes of the year, and with 100 of them to choose from, it wasn't easy! The four guests we'll be recapping with are: Lea Pica - A celebrity in the data storytelling and visualisation space. Richie and Lea cover the full picture of data presentation, how to understand your audience, how to leverage hollywood storytelling and more. Out December 19.Alex Banks - Founder of Sunday Signal. Adel and Alex cover Alex’s journey into AI and what led him to create Sunday Signal, the potential of AI, prompt engineering at its most basic level, chain of thought prompting, the future of LLMs and more. Out December 23.Don Chamberlin - The renowned co-inventor of SQL. Richie and Don explore the early development of SQL, how it became standardized, the future of SQL through NoSQL and SQL++ and more. Out December 26.Tom Tunguz - general Partner at Theory Ventures, a $235m VC firm. Richie and Tom explore trends in generative AI, cloud+local hybrid workflows, data security, the future of business intelligence and data analytics, AI in the corporate sector and more. Out December 30. Rapid change seems to be the new norm within the data and AI space, and due to the ecosystem constantly changing, it can be tricky to keep up. Fortunately, any self-respecting venture capitalist looking into data and AI will stay on top of what’s changing and where the next big breakthroughs are likely to come from. We all want to know which important trends are emerging and how we can take advantage of them, so why not learn from a leading VC. Tomasz Tunguz is a General Partner at Theory Ventures, a $235m early-stage venture capital firm. He blogs sat tomtunguz.com & co-authored Winning with Data. He has worked or works with Looker, Kustomer, Monte Carlo, Dremio, Omni, Hex, Spot, Arbitrum, Sui & many others. He was previously the product manager for Google's social media monetization team, including the Google-MySpace partnership, and managed the launches of AdSense into six new markets in Europe and Asia. Before Google, Tunguz developed systems for the Department of Homeland Security at Appian Corporation. In the episode, Richie and Tom explore trends in generative AI, the impact of AI on professional fields, cloud+local hybrid workflows, data security, and changes in data warehousing through the use of integrated AI tools, the future of business intelligence and data analytics, the challenges and opportunities surrounding AI in the corporate sector. You'll also get to discover Tom's picks for the hottest new data startups. Links Mentioned in the Show: Tom’s BlogTheory VenturesArticle: What Air Canada Lost In ‘Remarkable’ Lying AI Chatbot Case[Course] Implementing AI Solutions in BusinessRelated Episode: Making Better Decisions using Data & AI with Cassie Kozyrkov, Google's First Chief Decision ScientistSign up to RADAR: AI...
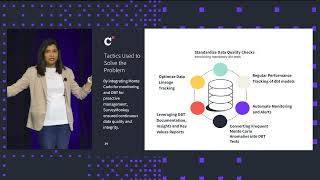
The data team at SurveyMonkey, the global leader in survey software, oversees heavy data transformation in dbt Cloud — both to power current business-critical projects, and also to migrate legacy workloads. Much of that transformation work is taking raw data — either from legacy databases or their cloud data warehouse (Snowflake) — and making it accessible and useful for downstream users. And to Samiksha Gour, Senior Data Engineering Manager at SurveyMonkey, each of these projects is not considered complete unless the proper checks, monitors, and alerts are in place.
Join Samiksha in this informative session as she walks through how her team uses dbt and their data observability platform Monte Carlo to ensure proper governance, gain efficiencies by eliminating duplicate testing and monitoring, and use data lineage to ensure upstream and downstream continuity for users and stakeholders.
Speaker: Samiksha Gour Senior Data Engineering Manager SurveyMonkey
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
Markov chain Monte Carlo (MCMC) methods, a class of iterative algorithms that allow sampling almost arbitrary probability distributions, have become increasingly popular and accessible to statisticians and scientists. But they run into difficulties when applied to multimodal probability distributions. These occur, for example, in Bayesian data analysis, when multiple regions in the parameter space explain the data equally well or when some parameters are redundant. Inaccurate sampling then results in incomplete and misleading parameter estimates. Markov chain Monte Carlo (MCMC) methods, a very popular class of iterative algorithms that allow sampling almost arbitrary probability distributions, run into difficulties when applied to multimodal probability distributions. These occur, for example, in Bayesian data analysis, when multiple regions in the parameter space explain the data equally well or when some parameters are redundant. In this talk, intended for data scientists and statisticians with basic knowledge of MCMC and probabilistic programming, I present Chainsail, an open-source web service written entirely in Python. It implements Replica Exchange, an advanced MCMC method designed specifically to improve sampling of multimodal distributions. Chainsail makes this algorithm easily accessible to users of probabilistic programming libraries by automatically tuning important parameters and exploiting easy on-demand provisioning of the (increased) computing resources necessary for running Replica Exchange.
Roche, is one of the world’s largest biotech companies, as well as a leading provider of in-vitro diagnostics and a global supplier of transformative innovative solutions across major disease areas. Over the past few years, they’ve undergone a migration to the cloud, adopted a modern data stack and implemented data mesh in order to double down on improving data reliability.
Join the data team at Roche to learn how they’ve leveraged data observability to support their sociotechnical shift to data mesh. They walk through their multi-year data observability journey, digging into how they implemented Monte Carlo in a global organization. They’ll also share their approach to data mesh at Roche and deep dive into a current use case.
Every day, banking institution Capital on Tap is calculating thousands of credit scores, directly impacting how their customers receive credit cards or additional lines of credit. Data quality is paramount – incorrect credit scores can set off a wide range of long-lasting financial implications for their customers, which is why the team turned to data observability with Monte Carlo, to improve their data – and credit score – reliability.
But, as with any new tool in your tech stack, onboarding new processes for key users is just as important as onboarding the tool itself.
Join this session with Ben Jones and Soren Rehn, to hear why the Analytics Engineering team at Capital on Tap decided to invest in a data observability tool, how their processes play a critical role in maximizing the tool’s value (including a few missteps and recalibrations along the way), and the strategies employed to garner widespread success and buy-in over time.
Summary Generative AI has rapidly gained adoption for numerous use cases. To support those applications, organizational data platforms need to add new features and data teams have increased responsibility. In this episode Lior Gavish, co-founder of Monte Carlo, discusses the various ways that data teams are evolving to support AI powered features and how they are incorporating AI into their work. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino.Your host is Tobias Macey and today I'm interviewing Lior Gavish about the impact of AI on data engineersInterview IntroductionHow did you get involved in the area of data management?Can you start by clarifying what we are discussing when we say "AI"?Previous generations of machine learning (e.g. deep learning, reinforcement learning, etc.) required new features in the data platform. What new demands is the current generation of AI introducing?Generative AI also has the potential to be incorporated in the creation/execution of data pipelines. What are the risk/reward tradeoffs that you have seen in practice?What are the areas where LLMs have proven useful/effective in data engineering?Vector embeddings have rapidly become a ubiquitous data format as a result of the growth in retrieval augmented generation (RAG) for AI applications. What are the end-to-end operational requirements to support this use case effectively?As with all data, the reliability and quality of the vectors will impact the viability of the AI application. What are the different failure modes/quality metrics/error conditions that they are subject to?As much as vectors, vector databases, RAG, etc. seem exotic and new, it is all ultimately shades of the same work that we have been doing for years. What are the areas of overlap in the work required for running the current generation of AI, and what are the areas where it diverges?What new skills do data teams need to acquire to be effective in supporting AI applications?What are the most interesting, innovative, or unexpected ways that you have seen AI impact data engineering teams?What are the most interesting, unexpected, or challenging lessons that you have learned while working with the current generation of AI?When is AI the wrong choice?What are your predictions for the future impact of AI on data engineering teams?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your Links Monte CarloPodcast EpisodeNLP == Natural Language ProcessingLarge Language ModelsGenerative AIMLOpsML EngineerFeature StoreRetrieval Augmented Generation (RAG)LangchainThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Generative AI's transformative power underscores the critical need for high-quality data. In this session, Barr Moses, CEO of Monte Carlo Data, Prukalpa Sankar, Cofounder at Atlan, and George Fraser, CEO at Fivetran, discuss the nuances of scaling data quality for generative AI applications, highlighting the unique challenges and considerations that come into play. Throughout the session, they share best practices for data and AI leaders to navigate these challenges, ensuring that governance remains a focal point even amid the AI hype cycle. Links Mentioned in the Show: Rewatch Session from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile app Empower your business with world-class data and AI skills with DataCamp for business