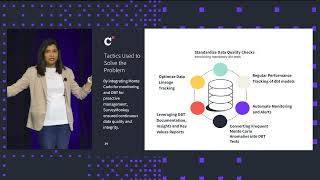
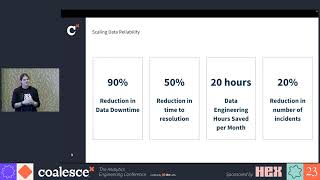
American Airlines, one of the largest airlines in the world, processes a tremendous amount of data every single minute. With a data estate of this scale, accountability for the data goes beyond the data team; the business organization has to be equally invested in championing the quality, reliability, and governance of data. In this session, Andrew Machen, Senior Manager, Data Engineering at American Airlines will share how his team maximizes resources to deliver reliable data at scale. He'll also outline his strategy for aligning business leadership with an investment in data reliability, and how leveraging Monte Carlo's data + AI observability platform enabled them to reduce time spent resolving data reliability issues from 10 weeks to 2 days, saving millions of dollars and driving valuable trust in the data.