Rapid change seems to be the new norm within the data and AI space, and due to the ecosystem constantly changing, it can be tricky to keep up. Fortunately, any self-respecting venture capitalist looking into data and AI will stay on top of what’s changing and where the next big breakthroughs are likely to come from. We all want to know which important trends are emerging and how we can take advantage of them, so why not learn from a leading VC. Tomasz Tunguz is a General Partner at Theory Ventures, a $235m early-stage venture capital firm. He blogs sat tomtunguz.com & co-authored Winning with Data. He has worked or works with Looker, Kustomer, Monte Carlo, Dremio, Omni, Hex, Spot, Arbitrum, Sui & many others. He was previously the product manager for Google's social media monetization team, including the Google-MySpace partnership, and managed the launches of AdSense into six new markets in Europe and Asia. Before Google, Tunguz developed systems for the Department of Homeland Security at Appian Corporation. In the episode, Richie and Tom explore trends in generative AI, the impact of AI on professional fields, cloud+local hybrid workflows, data security, and changes in data warehousing through the use of integrated AI tools, the future of business intelligence and data analytics, the challenges and opportunities surrounding AI in the corporate sector. You'll also get to discover Tom's picks for the hottest new data startups. Links Mentioned in the Show: Tom’s BlogTheory VenturesArticle: What Air Canada Lost In ‘Remarkable’ Lying AI Chatbot Case[Course] Implementing AI Solutions in BusinessRelated Episode: Making Better Decisions using Data & AI with Cassie Kozyrkov, Google's First Chief Decision ScientistSign up to RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
 talk-data.com
talk-data.com
Topic
Monte Carlo
106
tagged
Activity Trend
Top Events
Governance is difficult for an organization of any size, and many struggle to execute on data management in an efficient manner. At Assurance, the team has utilized Starburst Galaxy to embed ownership within the data mesh framework, completely transforming the way organizations handle data. By granting data owners complete control and visibility over their data, Assurance enables a more nuanced and effective approach to data management. This approach not only fosters a sense of responsibility but also ensures that data is relevant, up-to-date, and aligned with the evolving needs of the organization. In this presentation, Shen Weng and Mitchell Polsons will discuss the strategic implementation of compute ownership in Starburst Galaxy, showing how it empowers teams to identify and resolve issues quickly, significantly improving the uptime of key computing operations. This approach is vital for achieving operational excellence, characterized by enhanced efficiency, reliability, and quality. Additionally, the new data setup has enabled the Assurance team to simplify data transformation processes using dbt and to improve data quality monitoring with Monte Carlo, further streamlining and strengthening our data management practices.
We talked about:
Rob’s background Going from software engineering to Bayesian modeling Frequentist vs Bayesian modeling approach About integrals Probabilistic programming and samplers MCMC and Hakaru Language vs library Encoding dependencies and relationships into a model Stan, HMC (Hamiltonian Monte Carlo) , and NUTS Sources for learning about Bayesian modeling Reaching out to Rob
Links:
Book 1: https://bayesiancomputationbook.com/welcome.html Book/Course: https://xcelab.net/rm/statistical-rethinking/
Free ML Engineering course: http://mlzoomcamp.com Join DataTalks.Club: https://datatalks.club/slack.html Our events: https://datatalks.club/events.html
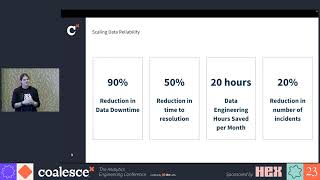
TOCA Football, the largest operator of indoor soccer centers in North America, leverages accurate data to power analytics for over 30 training centers, providing everything from operational insights for executives to ball-by-ball analysis.
In 2020, the team adopted a cloud-native data stack with dbt to scale analytics enablement for the go-to-market org, including the company’s finance, strategy, operations, and marketing teams. By 2022, their lean team of four was struggling to gain visibility into the health and performance of their dbt models. So, what was the TOCA team to do? Two words: data observability.
In this talk, Sam Cvetkovski, Director, Data & Analytics discusses how TOCA built their larger data observability strategy to reduce model bloat, increase data accuracy, and boost stakeholder satisfaction with their team’s data products. She shares her biggest “aha!” moments, key challenges, and best practices for teams getting started on their dbt reliability journeys.
Speakers: Sam Cvetkovski, Director, Data & Analytics, TOCA Football; Barr Moses, Co-Founder & CEO, Monte Carlo
Register for Coalesce at https://coalesce.getdbt.com
Summary
As businesses increasingly invest in technology and talent focused on data engineering and analytics, they want to know whether they are benefiting. So how do you calculate the return on investment for data? In this episode Barr Moses and Anna Filippova explore that question and provide useful exercises to start answering that in your company.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack Your host is Tobias Macey and today I'm interviewing Barr Moses and Anna Filippova about how and whether to measure the ROI of your data team
Interview
Introduction How did you get involved in the area of data management? What are the typical motivations for measuring and tracking the ROI for a data team?
Who is responsible for collecting that information? How is that information used and by whom?
What are some of the downsides/risks of tracking this metric? (law of unintended consequences) What are the inputs to the number that constitutes the "investment"? infrastructure, payroll of employees on team, time spent working with other teams? What are the aspects of data work and its impact on the business that complicate a calculation of the "return" that is generated? How should teams think about measuring data team ROI? What are some concrete ROI metrics data teams can use?
What level of detail is useful? What dimensions should be used for segmenting the calculations?
How can visibility into this ROI metric be best used to inform the priorities and project scopes of the team? With so many tools in the modern data stack today, what is the role of technology in helping drive or measure this impact? How do your respective solutions, Monte Carlo and dbt, help teams measure and scale data value? With generative AI on the upswing of the hype cycle, what are the impacts that you see it having on data teams?
What are the unrealistic expectations that it will produce? How can it speed up time to delivery?
What are the most interesting, innovative, or unexpected ways that you have seen data team ROI calculated and/or used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on measuring the ROI of data teams? When is measuring ROI the wrong choice?
Contact Info
Barr
Anna
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Monte Carlo
Podcast Episode
dbt
Podcast Episode
JetBlue Snowflake Con Presentation Generative AI Large Language Models
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Rudderstack: 
Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guessw

Comcast Effectv, the 2,000-employee advertising wing of Comcast, America’s largest telecommunications company, provides custom video ad solutions powered by aggregated viewership data. As a global technology and media company connecting millions of customers to personalized experiences and processing billions of transactions, Comcast Effectv was challenged with handling massive loads of data, monitoring hundreds of data pipelines, and managing timely coordination across data teams.
In this session, we will discuss Comcast Effectv’s journey to building a more scalable, reliable lakehouse and driving data observability at scale with Monte Carlo. This has enabled Effectv to have a single pane of glass view of their entire data environment to ensure consumer data trust across their entire AWS, Databricks, and Looker environment.
Talk by: Scott Lerner and Robinson Creighton
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc
You’ve got your pipelines flowing … how much do you know about the data inside? Most teams have some coverage with unit/contract/expectations tests, and you might have other quality checks. But it can be very ad-hoc and disorganized. You want to do more to beef up data quality and observability … does that mean you just need to write more tests and assertions? Come learn about the best way to see your data’s quality alongside DAGs in a familiar context. We’ll review 3 common tools to get a handle on quality in a cohesive way across all your DAGs: Great Expectations Monte Carlo Data Databand
As organizations of all sizes continuously look to drive value out of data, the modern data stack has emerged as a clear solution for getting insights into the hands of the organization. With the rapid pace of innovation not slowing down, the tools within the modern data stack have enabled data teams to drive faster insights, collaborate at scale, and democratize data knowledge. However, are tools just enough to drive business value with data? In the first of our four RADAR 2023 sessions, we look at the key drivers of value within the modern data stack through the minds of Yali Sassoon and Barr Moses. Yali Sassoon is the Co-Founder and Chief Strategy Officer at Snowplow Analytics, a behavioral data platform that empowers data teams to solve complex data challenges. At Snowplow, Yali gets to combine his love of building things with his fascination of the ways in which people use data to reason. Barr Moses is CEO & Co-Founder of Monte Carlo. Previously, she was VP Customer Operations at customer success company Gainsight, where she helped scale the company 10x in revenue and, among other functions, built the data/analytics team. Listen in as Yali and Barr outline how data leaders can drive value creation with data in 2023.
In order for any data team to move from reactive to proactive and drive revenue for the business, they must make sure the basics are in place and that the team and data culture is mature enough to allow for scalable return on investment. Without these elements, data teams find themselves unable to make meaningful progress because they are stuck reacting to problems and responding to rudimentary questions from stakeholders across the organization. This quickly takes up bandwidth and keeps them from achieving meaningful ROI. In today’s episode, we have invited Shane Murray to break down how to effectively structure a data team, how data leaders can lead efficient decentralization, and how teams can scale their ROI in 2023. Shane is the Field CTO at Monte Carlo, a data reliability company that created the industry's first end-to-end Data Observability platform. Shane’s career has taken him through a successful 9-year tenure at The New York Times, where he grew the data analytics team from 12 to 150 people and managed all core data products. Shane is an expert when it comes to data observability, enabling effective ROI for data initiatives, scaling high-impact data teams, and more. Throughout the episode we discuss how to structure a data team for maximum efficiency, how data leaders can balance long-term and short-term data initiatives, how data maturity correlates to a team’s forward-thinking ability, data democratization with data insights and reporting ROI, best practices for change management, and much more.
When it comes to data, there are data consumers (analysts, builders and users of data products, and various other business stakeholders) and data producers (software engineers and various adjacent roles and systems). It's all too common for data producers to "break" the data as they add new features and functionality to systems as they focus on the operational processes the system supports and not the data that those processes spawn. How can this be avoided? One approach is to implement "data contracts." What that actually means… is the subject of this episode, which Shane Murray from Monte Carlo joined us to discuss! For complete show notes, including links to items mentioned in this episode and a transcript of the show, visit the show page.
Summary
The modern data stack has made it more economical to use enterprise grade technologies to power analytics at organizations of every scale. Unfortunately it has also introduced new overhead to manage the full experience as a single workflow. At the Modern Data Company they created the DataOS platform as a means of driving your full analytics lifecycle through code, while providing automatic knowledge graphs and data discovery. In this episode Srujan Akula explains how the system is implemented and how you can start using it today with your existing data systems.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Truly leveraging and benefiting from streaming data is hard - the data stack is costly, difficult to use and still has limitations. Materialize breaks down those barriers with a true cloud-native streaming database - not simply a database that connects to streaming systems. With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. Go to dataengineeringpodcast.com/materialize today and sign up for early access to get started. If you like what you see and want to help make it better, they're hiring across all functions! Struggling with broken pipelines? Stale dashboards? Missing data? If this resonates with you, you’re not alone. Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo monitors and alerts for data issues across your data warehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box. Start trusting your data with Monte Carlo today! Visit dataengineeringpodcast.com/montecarlo to learn more. Data and analytics leaders, 2023 is your year to sharpen your leadership skills, refine your strategies and lead with purpose. Join your peers at Gartner Data & Analytics Summit, March 20 – 22 in Orlando, FL for 3 days of expert guidance, peer networking and collaboration. Listeners can save $375 off standard rates with code GARTNERDA. Go to dataengineeringpodcast.com/gartnerda today to find out more. Your host is Tobias Macey and today I'm interviewing Srujan Akula about DataOS, a pre-integrated and managed data platform built by The Modern Data Company
Interview
Introduction How did you get involved in the area of data management? Can you describe what your mission at The Modern Data Company is and the story behind it? Your flagship (only?) product is a platform that you're calling DataOS. What is the scope and goal of that platform?
Who is the target audience?
On your site you refer to the idea of "data as software". What are the principles and ways of thinking that are encompassed by that concept?
What are the platform capabilities that are required to make it possible?
There are 11 "Key Features" listed on your site for the DataOS. What was your process for identifying the "must have" vs "nice to have" features for launching the platform? Can you describe the technical architecture that powers your DataOS product?
What are the core principles that you are optimizing for in the design of your platform? How have the design and goals of the system changed or evolved since you started working on DataOS?
Can you describe the workflow for the different practitioners and stakeholders working on an installation of DataOS? What are the interfaces and escape hatches that are available for integrating with and ext
Summary
Managing end-to-end data flows becomes complex and unwieldy as the scale of data and its variety of applications in an organization grows. Part of this complexity is due to the transformation and orchestration of data living in disparate systems. The team at Upsolver is taking aim at this problem with the latest iteration of their platform in the form of SQLake. In this episode Ori Rafael explains how they are automating the creation and scheduling of orchestration flows and their related transforations in a unified SQL interface.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Data and analytics leaders, 2023 is your year to sharpen your leadership skills, refine your strategies and lead with purpose. Join your peers at Gartner Data & Analytics Summit, March 20 – 22 in Orlando, FL for 3 days of expert guidance, peer networking and collaboration. Listeners can save $375 off standard rates with code GARTNERDA. Go to dataengineeringpodcast.com/gartnerda today to find out more. Truly leveraging and benefiting from streaming data is hard - the data stack is costly, difficult to use and still has limitations. Materialize breaks down those barriers with a true cloud-native streaming database - not simply a database that connects to streaming systems. With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. Go to dataengineeringpodcast.com/materialize today and sign up for early access to get started. If you like what you see and want to help make it better, they're hiring across all functions! Struggling with broken pipelines? Stale dashboards? Missing data? If this resonates with you, you’re not alone. Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo monitors and alerts for data issues across your data warehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box. Start trusting your data with Monte Carlo today! Visit dataengineeringpodcast.com/montecarlo to learn more. Your host is Tobias Macey and today I'm interviewing Ori Rafael about the SQLake feature for the Upsolver platform that automatically generates pipelines from your queries
Interview
Introduction How did you get involved in the area of data management? Can you describe what the SQLake product is and the story behind it?
What is the core problem that you are trying to solve?
What are some of the anti-patterns that you have seen teams adopt when designing and implementing DAGs in a tool such as Airlow? What are the benefits of merging the logic for transformation and orchestration into the same interface and dialect (SQL)? Can you describe the technical implementation of the SQLake feature? What does the workflow look like for designing and deploying pipelines in SQLake? What are the opportunities for using utilities such as dbt for managing logical complexity as the number of pipelines scales?
SQL has traditionally been challenging to compose. How did that factor into your design process for how to structure the dialect extensions for job scheduling?
What are some of the complexities that you have had to address in your orchestration system to be able to manage timeliness of operations as volume and complexity of the data scales? What are some of the edge cases that you have had to provide escape hatches for? What are the most interesting, innova
Summary
Making effective use of data requires proper context around the information that is being used. As the size and complexity of your organization increases the difficulty of ensuring that everyone has the necessary knowledge about how to get their work done scales exponentially. Wikis and intranets are a common way to attempt to solve this problem, but they are frequently ineffective. Rehgan Avon co-founded AlignAI to help address this challenge through a more purposeful platform designed to collect and distribute the knowledge of how and why data is used in a business. In this episode she shares the strategic and tactical elements of how to make more effective use of the technical and organizational resources that are available to you for getting work done with data.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you're ready to build your next pipeline, or want to test out the projects you hear about on the show, you'll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don't forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Struggling with broken pipelines? Stale dashboards? Missing data? If this resonates with you, you’re not alone. Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo monitors and alerts for data issues across your data warehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box. Start trusting your data with Monte Carlo today! Visit dataengineeringpodcast.com/montecarlo to learn more. Your host is Tobias Macey and today I'm interviewing Rehgan Avon about her work at AlignAI to help organizations standardize their technical and procedural approaches to working with data
Interview
Introduction How did you get involved in the area of data management? Can you describe what AlignAI is and the story behind it? What are the core problems that you are focused on addressing?
What are the tactical ways that you are working to solve those problems?
What are some of the common and avoidable ways that analytics/AI projects go wrong?
What are some of the ways that organizational scale and complexity impacts their ability to execute on data and AI projects?
What are the ways that incomplete/unevenly distributed knowledge manifests in project design and execution? Can you describe the design and implementation of the AlignAI platform?
How have the goals and implementation of the product changed since you
Summary
Five years of hosting the Data Engineering Podcast has provided Tobias Macey with a wealth of insight into the work of building and operating data systems at a variety of scales and for myriad purposes. In order to condense that acquired knowledge into a format that is useful to everyone Scott Hirleman turns the tables in this episode and asks Tobias about the tactical and strategic aspects of his experiences applying those lessons to the work of building a data platform from scratch.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you're ready to build your next pipeline, or want to test out the projects you hear about on the show, you'll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don't forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Struggling with broken pipelines? Stale dashboards? Missing data? If this resonates with you, you’re not alone. Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo monitors and alerts for data issues across your data warehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box. Start trusting your data with Monte Carlo today! Visit dataengineeringpodcast.com/montecarlo to learn more. Your host is Tobias Macey and today I'm being interviewed by Scott Hirleman about my work on the podcasts and my experience building a data platform
Interview
Introduction How did you get involved in the area of data management?
Data platform building journey
Why are you building, who are the users/use cases How to focus on doing what matters over cool tools How to build a good UX Anything surprising or did you discover anything you didn't expect at the start How to build so it's modular and can be improved in the future
General build vs buy and vendor selection process
Obviously have a good BS detector - how can others build theirs So many tools, where do you start - capability need, vendor suite offering, etc. Anything surprising in doing much of this at once How do you think about TCO in build versus buy Any advice
Guest call out
Be brave, believe you are good enough to be on the show Look at past episodes and don't pitch the same as what's been on recently And vendors, be smart, work with your customers to come up with a good pitch for them as guests...
Tobias' advice and learnings from building out a data platform:
Advice: when considering a tool, start from what are you act
Summary
One of the reasons that data work is so challenging is because no single person or team owns the entire process. This introduces friction in the process of collecting, processing, and using data. In order to reduce the potential for broken pipelines some teams have started to adopt the idea of data contracts. In this episode Abe Gong brings his experiences with the Great Expectations project and community to discuss the technical and organizational considerations involved in implementing these constraints to your data workflows.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you're ready to build your next pipeline, or want to test out the projects you hear about on the show, you'll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don't forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Struggling with broken pipelines? Stale dashboards? Missing data? If this resonates with you, you’re not alone. Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo monitors and alerts for data issues across your data warehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box. Start trusting your data with Monte Carlo today! Visit dataengineeringpodcast.com/montecarlo to learn more. Your host is Tobias Macey and today I'm interviewing Abe Gong about the technical and organizational implementation of data contracts
Interview
Introduction How did you get involved in the area of data management? Can you describe what your conception of a data contract is?
What are some of the ways that you have seen them implemented?
How has your work on Great Expectations influenced your thinking on the strategic and tactical aspects of adopting/implementing data contracts in a given team/organization?
What does the negotiation process look like for identifying what needs to be included in a contract?
What are the interfaces/integration points where data contracts are most useful/necessary? What are the discussions that need to happen when deciding when/whether a contract "violation" is a blocking action vs. issuing a notification? At what level of detail/granularity are contracts most helpful? At the technical level, what does the implementation/integration/deployment of a contract look like? What are the most interesting, innovative, or unexpected ways that you have seen data contracts used? What are the most interesting, unexpected, or chall
Summary Business intelligence is the foremost application of data in organizations of all sizes. The typical conception of how it is accessed is through a web or desktop application running on a powerful laptop. Zing Data is building a mobile native platform for business intelligence. This opens the door for busy employees to access and analyze their company information away from their desk, but it has the more powerful effect of bringing first-class support to companies operating in mobile-first economies. In this episode Sabin Thomas shares his experiences building the platform and the interesting ways that it is being used.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Data engineers don’t enjoy writing, maintaining, and modifying ETL pipelines all day, every day. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc., are already available as plug-and-play connectors with reliable, intuitive SaaS solutions. Hevo Data is a highly reliable and intuitive data pipeline platform used by data engineers from 40+ countries to set up and run low-latency ELT pipelines with zero maintenance. Boasting more than 150 out-of-the-box connectors that can be set up in minutes, Hevo also allows you to monitor and control your pipelines. You get: real-time data flow visibility, fail-safe mechanisms, and alerts if anything breaks; preload transformations and auto-schema mapping precisely control how data lands in your destination; models and workflows to transform data for analytics; and reverse-ETL capability to move the transformed data back to your business software to inspire timely action. All of this, plus its transparent pricing and 24*7 live support, makes it consistently voted by users as the Leader in the Data Pipeline category on review platforms like G2. Go to dataengineeringpodcast.com/hevodata and sign up for a free 14-day trial that also comes with 24×7 support. Struggling with broken pipelines? Stale dashboards? Missing data? If this resonates with you, you’re not alone. Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo monitors and alerts for data issues across your data warehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Monte Carlo also gives you a holistic picture
Summary The data ecosystem has been growing rapidly, with new communities joining and bringing their preferred programming languages to the mix. This has led to inefficiencies in how data is stored, accessed, and shared across process and system boundaries. The Arrow project is designed to eliminate wasted effort in translating between languages, and Voltron Data was created to help grow and support its technology and community. In this episode Wes McKinney shares the ways that Arrow and its related projects are improving the efficiency of data systems and driving their next stage of evolution.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Struggling with broken pipelines? Stale dashboards? Missing data? If this resonates with you, you’re not alone. Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo monitors and alerts for data issues across your data warehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box. Start trusting your data with Monte Carlo today! Visit dataengineeringpodcast.com/montecarlo to learn more. Data engineers don’t enjoy writing, maintaining, and modifying ETL pipelines all day, every day. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc., are already available as plug-and-play connectors with reliable, intuitive SaaS solutions. Hevo Data is a highly reliable and intuitive data pipeline platform used by data engineers from 40+ countries to set up and run low-latency ELT pipelines with zero maintenance. Boasting more than 150 out-of-the-box connectors that can be set up in minutes, Hevo also allows you to monitor and control your pipelines. You get: real-time data flow visibility, fail-safe mechanisms, and alerts if anything breaks; preload transformations and auto-schema mapping precisely control how data lands in your destination; models and workflows to transform data for analytics; and reverse-ETL capability to move the transformed data back to your business software to inspire timely action. All of this, plus its transparent pricing and 24*7 live support, makes it consistently voted by users as the Leader in the Data Pipeline category on review platforms like G2. Go to dataengineeringpodcast.com/hevodata and sign up for a free 14-day trial that also comes with 24×7 support. Your host is Tobias Macey and today I’m interviewing Wes McKinney about his work at Voltron Data and on the Arrow ecosystem
Interview
Introduction How did you get involved in the area of data management? Can you describe what you are building at Voltron Data and the story behind it? What is the vision for the broader data ecosystem that you are trying to realize through your investment in Arrow and related projects?
How does your work at Voltron Data contribute to the realization of that vision?
What is the impact on engineer productivity and compute efficiency that gets introduced by the impedance mismatches between language and framework representations of data? The scope and capabilities of the Arrow project have grown substantially since it was first introduced. Can you give an overview of the current features and extensions to the project? What are some of the ways that ArrowVe and its related projects can be integrated with or replace the different elements of a data platform? Can you describe how Arrow is implemented?
What are the most complex/challenging aspects of the engineering needed to support interoperable data interchange between language runtimes?
How are you balancing the desire to move quickly and improve the Arrow protocol and implementations, with the need to wait for other players in the ecosystem (e.g. database engines, compute frameworks, etc.) to add support? With the growing application of data formats such as graphs and vectors, what do you see as the role of Arrow and its ideas in those use cases? For workflows that rely on integrating structured and unstructured data, what are the options for interaction with non-tabular data? (e.g. images, documents, etc.) With your support-focused business model, how are you approaching marketing and customer education to make it viable and scalable? What are the most interesting, innovative, or unexpected ways that you have seen Arrow used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on Arrow and its ecosystem? When is Arrow the wrong choice? What do you have planned for the future of Arrow?
Contact Info
Website wesm on GitHub @wesmckinn on Twitter
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don’t forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you’ve learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Voltron Data Pandas
Podcast Episode
Apache Arrow Partial Differential Equation FPGA == Field-Programmable Gate Array GPU == Graphics Processing Unit Ursa Labs Voltron (cartoon) Feature Engineering PySpark Substrait Arrow Flight Acero Arrow Datafusion Velox Ibis SIMD == Single Instruction, Multiple Data Lance DuckDB
Podcast Episode
Data Threads Conference Nano-Arrow Arrow ADBC Protocol Apache Iceberg
Podcast Episode
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Atlan: 
Have you ever woken up to a crisis because a number on a dashboard is broken and no one knows why? Or sent out frustrating slack messages trying to find the right data set? Or tried to understand what a column name means?
Our friends at Atlan started out as a data team themselves and faced all this collaboration chaos themselves, and started building Atlan as an internal tool for themselves. Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. By acting as a virtual hub for data assets ranging from tables and dashboards to SQL snippets & code, Atlan enables teams to create a single source of truth for all their data assets, and collaborate across the modern data stack through deep integrations with tools like Snowflake, Slack, Looker and more.
Go to dataengineeringpodcast.com/atlan and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription.a href="https://dataengineeringpodcast.com/montecarlo"…

Leverage the full power of Bayesian analysis for competitive advantage Bayesian methods can solve problems you can't reliably handle any other way. Building on your existing Excel analytics skills and experience, Microsoft Excel MVP Conrad Carlberg helps you make the most of Excel's Bayesian capabilities and move toward R to do even more. Step by step, with real-world examples, Carlberg shows you how to use Bayesian analytics to solve a wide array of real problems. Carlberg clarifies terminology that often bewilders analysts, provides downloadable Excel workbooks you can easily adapt to your own needs, and offers sample R code to take advantage of the rethinking package in R and its gateway to Stan. As you incorporate these Bayesian approaches into your analytical toolbox, you'll build a powerful competitive advantage for your organization---and yourself. Explore key ideas and strategies that underlie Bayesian analysis Distinguish prior, likelihood, and posterior distributions, and compare algorithms for driving sampling inputs Use grid approximation to solve simple univariate problems, and understand its limits as parameters increase Perform complex simulations and regressions with quadratic approximation and Richard McElreath's quap function Manage text values as if they were numeric Learn today's gold-standard Bayesian sampling technique: Markov Chain Monte Carlo (MCMC) Use MCMC to optimize execution speed in high-complexity problems Discover when frequentist methods fail and Bayesian methods are essential---and when to use both in tandem ...

When Prateek Chawla, founding engineer, joined Monte Carlo in 2019, he was responsible for spinning up our data platform from scratch. He was more of a backend/cloud engineer, but like with any startup had to wear many hats, so got the opportunity to play the role of data engineer too. In this talk, we’ll walk through how we spun up Monte Calro’s data stack with Snowflake, Looker, and dbt, touching on how and why we implemented dbt (and later, dbt Cloud), key use cases, and handy tricks for integrating dbt with other popular tools, like Airflow, and Spark. We’ll discuss what worked, what didn’t work, and other lessons learned along the way, as well as share how our data stack evolved over time to scale to meet the demands of our growing startup. We’ll also touch on a very critical component of the dbt value proposition, data quality testing, and discuss some of our favorite tests and what we’ve done to automate and integrate them with other elements of our stack.
Coalesce 2023 is coming! Register for free at https://coalesce.getdbt.com/.

Lineage is a critical component of any root cause, impact analysis, and overall analytics heath assessment workflow. But it hasn’t always been easy to create, particularly at the field level. In this session, Mei Tao, Helena Munoz, and Xuanzi Han (Monte Carlo) tackle this challenge head-on by leveraging some of the most popular tools in the modern data stack, including dbt, Airflow, Snowflake, and ANother Tool for Language Recognition (ANTLR). Learn how they designed the data model, query parser, and larger database design for field-level lineage—highlighting learnings, wrong turns, and best practices developed along the way.
Coalesce 2023 is coming! Register for free at https://coalesce.getdbt.com/.