A theoretical talk on the impact of AI on work, life and society.
 talk-data.com
talk-data.com
Topic
AI/ML
Artificial Intelligence/Machine Learning
data_science
algorithms
predictive_analytics
9014
tagged
Activity Trend
1532
peak/qtr
2020-Q1
2026-Q2
Top Events
Google Cloud Next '25
761
Microsoft Ignite 2025
699
Google Cloud Next '24
553
Data + AI Summit 2025
425
O'Reilly Data Science Books
333
Databricks DATA + AI Summit 2023
287
Data Engineering Podcast
271
O'Reilly Data Engineering Books
240
DataFramed
239
Making Data Simple
223
AWS re:Invent 2024
223
DATA MINER Big Data Europe Conference 2020
215
A technical demo breaking down the process for building a product using AI with real-life learnings and insights.

AI is transforming data careers. Roles once centered on modeling and feature engineering are evolving into positions that involve building AI products, crafting prompts, and managing workflows shaped by automation and augmentation. In this panel discussion, ambassadors from Women in Data Science (WiDS) share how they have adapted through this shift—turning personal experiments into company practices, navigating uncertainty, and redefining their professional identities. They’ll also discuss how to future-proof your career by integrating AI into your daily work and career growth strategy. Attendees will leave with a clearer view of how AI is reshaping data careers and practical ideas for how to evolve their own skills, direction, and confidence in an era where AI is not replacing, but redefining, human expertise.

What does the JupyterLab extension ecosystem actually look like in 2025? While extensions drive much of JupyterLab's practical value, their overall landscape remains largely unexplored. This talk analyzes public PyPI (via BigQuery) and GitHub data to quantify growth, momentum, and health: monthly downloads by category, release recency, star-download relationships, and the rise of AI-focused extensions. I will present my approach for building this analysis pipeline and offer lessons learned. Finally, I will demonstrate of an open, read-only web catalog built on this data set.
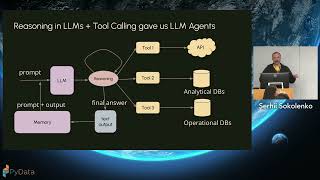
The AI landscape is abuzz with talk of "agentic intelligence" and "autonomous reasoning." But beneath the hype, a quieter revolution is underway: Small Language Models (SLMs) are starting to perform the core reasoning and orchestration tasks once thought to require massive LLMs. In this talk, we’ll demystify the current state of “AI agents,” show how compact models like Phi-2, xLAM 8B, and Nemotron-H 9B can plan, reason, and call tools effectively, and demonstrate how you can deploy them on consumer-grade hardware. Using Python and lightweight frameworks such as LangChain, we’ll show how anyone can quickly build and experiment with their own local agentic systems. Attendees will leave with a grounded understanding of agent architectures, SLM capabilities, and a roadmap for running useful agents without the GPU farm.

This talk covers methods of evaluating AI Agents, with an example of how the speakers built a Python-based evaluation framework for a user-facing AI Agent system which has been in production for over a year. We share tools and Python frameworks used (as well as tradeoffs and alternatives), and discuss methods such as LLM-as-Judge, rules-based evaluations, ML metrics used, as well as selection tradeoffs.
Program Synthesis (PS) is the task of automatically generating logical procedures or source code from a small set of input-output examples. While LLMs and agents dominate current AI conversations, they often struggle with these kinds of precise reasoning tasks—where smaller, well-structured models for PS can succeed. In this talk, we’ll walk through the end-to-end development of an PS system, covering dataset representation using graph structures, model architectures, and tree search algorithms. The working example for this talk is the generation of procedural textures for 3D modeling, but the methodology is domain-agnostic. Participants will leave with a deeper understanding of PS, its real-world potential, and the trade-offs between different architectural approaches. The session is designed for practitioners with a solid understanding of ML concepts and some familiarity with NN architectures such as transformers and CNNs.

Your LLM evaluation suite shows 93% accuracy. Then domain experts point out it's producing catastrophically wrong answers for real-world use cases. This talk explores the collaboration gap between AI engineers and domain experts that technical evaluation alone cannot bridge. Drawing from government, healthcare, and civic tech case studies, we'll examine why tools like PromptFoo, DeepEval, and RAGAS are necessary but insufficient and how structured collaboration with domain stakeholders reveals critical failures invisible to standard metrics. You'll leave with practical starting points for building cross-functional evaluation that catches problems before deployment.
In this talk, I will walk through how building data products is evolving with modern AI development tools. I’ll take you through a small end-to-end product I built in my free time—covering everything from design, to frontend development, to data collection, and ultimately to building data science components. Here is the link to the project https://stateoftheartwithai.com/
Building accurate AI workflows can get complicated fast. By explicitly defining and modularizing agent tasks, my AI flows have become more precise, consistent, and efficient—delivering improved outcomes consistently. But can we prove it? In this talk, I'll walk you through an agentic app built with Langflow, and show how giving agents narrower, well-defined tasks leads directly to more accurate, consistent results. We'll put that theory to the test using evals with Pytest and LangSmith, iterating across different agent setups, analyzing data, and tightening up the app. By the end, we'll have a clear, repeatable workflow that lets us have confidence in how future agent or LLM changes will affect outcomes, before we ever hit deploy.

Geospatial analysis often relies on raster data, n‑dimensional arrays where each cell holds a spatial measurement. Many raster operations, such as computing indices, statistical analysis, and classification, are naturally parallelizable and ideal for GPU acceleration.
This talk demonstrates an end‑to‑end GPU‑accelerated semantic segmentation pipeline for classifying satellite imagery into multiple land cover types. Starting with cloud-hosted imagery, we will process data in chunks, compute features, train a machine learning model, and run large-scale predictions. This process is accelerated with the open-source RAPIDS ecosystem, including Xarray, cuML, and Dask, often requiring only minor changes to familiar data science workflows.
Attendees who work with raster data or other parallelizable, computationally intensive workflows will benefit most from this talk, which focuses on GPU acceleration techniques. While the talk draws from geospatial analysis, key geospatial concepts will be introduced for beginners. The methods demonstrated can be applied broadly across domains to accelerate large-scale data processing.

The time series machine learning community has begun adopting foundational models for forecasting and anomaly detection. These models, such as TimeGPT, MOMENT, Morai, and Chronos, offer zero-shot learning and promise to accelerate the development of AI use cases.
In this talk, we'll explore two popular foundational models, TimeGPT and MOMENT, for Time Series Anomaly Detection (TSAD). We'll specifically focus on the Novelty Detection flavor of TSAD, where we only have access to nominal (normal) data and the goal is to detect deviations from this norm.
TimeGPT and MOMENT take fundamentally different approaches to novelty detection.
• TimeGPT uses a forecasting-based method, tracking observed data against its forecasted confidence intervals. An anomaly is flagged when an observation falls sufficiently outside these intervals.
• MOMENT, an open-source model, uses a reconstruction-based approach. The model first encodes nominal data, then characterizes the reconstruction errors. During inference, it compares the test data's reconstruction error to these characterized values to identify anomalies.
We'll detail these approaches using the UCR anomaly detection dataset. The talk will highlight potential pitfalls when using these models and compare them with traditional TSAD algorithms.
This talk is geared toward data scientists interested in the nuances of applying foundational models for TSAD. No prior knowledge of time series anomaly detection or foundational models is required.

Tree-based machine learning models such as XGBoost, LightGBM, and CatBoost are widely used, but understanding their predictions remains challenging. SHAP (SHapley Additive exPlanations) provides feature attributions based on Shapley values, yet its assumptions — feature independence, additivity, and consistency — are often violated in practice, potentially producing misleading explanations. This talk critically examines SHAP’s limitations in tree-based models and introduces TreeSHAP, its specialized implementation for decision trees. Rather than presenting it as perfect, we evaluate its effectiveness, highlighting where it succeeds and where explanations remain limited. Attendees will gain a practical, critical understanding of SHAP and TreeSHAP, and strategies for interpreting tree-based models responsibly.
Target audience: Data scientists, ML engineers, and analysts familiar with tree-based models. Background: Basic understanding of feature importance and model interpretability.
AI red teaming is crucial for identifying security and safety vulnerabilities (e.g., jailbreaks, prompt injection, harmful content generation) of Large Language Models. However, manual and brute-force adversarial testing is resource-intensive and often inefficiently consumes time and compute resources exploring low-risk regions of the input space. This talk introduces a practical, Python-based methodology for accelerating red teaming using model uncertainty quantification (UQ).
Machine learning often assumes clean, high-quality data. Yet the real world is noisy, incomplete, and messy, and models trained only on sanitized datasets become brittle. This talk explores the counterintuitive idea that deliberately corrupting data during training can make models more robust. By adding structured noise, masking inputs, or flipping labels, we can prevent overfitting, improve generalization, and build systems that survive real world conditions. Attendees will leave with a clear understanding of why “bad data” can sometimes lead to better models.

AWS is accelerating Web3 development across diverse use cases, including AI agents entering the digital economy, through core infrastructure, specialized offerings, and partner solutions. Join AWS and Coinbase to dive deep into the fundamental building blocks and full-stack architecture where AI agents, powered by Amazon Bedrock, execute digital assets payments using open payment protocols over a public blockchain. To ensure transaction security, these agents are equipped with wallets built on AWS Nitro Enclaves. Join this session to learn how to leverage AWS and Coinbase technologies to shape the future of autonomous online payments.
Learn more: More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.
AWSreInvent #AWSreInvent2025 #AWS
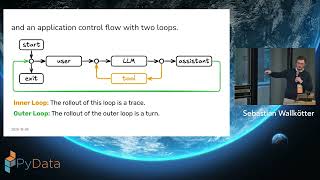
Do you feel lost in the jungle of GenAI frameworks and buzzwords? Here's a way out. Take any GenAI app, peel away the fluff, and look at its core. You'll find the same pattern: a boringly simple nested while loop. I will show you how this loop produces chat assistants, AI agents, and multi-agent systems. Then we'll cover how RAG, tool-calling, and memory are like lego bricks we add as needed. This gives you a first-principles based map. Use it to build GenAI apps from scratch; no frameworks needed.

Advances in large language models (LLMs) have propelled a recent flurry of AI tools for data management and operations. For example, AI-powered code assistants leverage LLMs to generate code for dataflow pipelines. RAG pipelines enable LLMs to ground responses with relevant information from external data sources. Data agents leverage LLMs to turn natural language questions into data-driven answers and actions. While challenges remain, these advances are opening exciting new opportunities for data scientists and engineers. In this talk, we will examine recent advances, along with some still incubating in research labs, with the goal of understanding where this is all heading, and present our perspective on what’s next for AI in data management and data operations.
A 30-minute talk examining key trends from 2025, how AI intersected with platform engineering, and current best practices and frameworks for doing "great" platform engineering.
Retours d'expérience sur le sujet