Está no ar, o Data Hackers News !! Os assuntos mais quentes da semana, com as principais notícias da área de Dados, IA e Tecnologia, que você também encontra na nossa Newsletter semanal, agora no Podcast do Data Hackers !! Aperte o play e ouça agora, o Data Hackers News dessa semana ! Para saber tudo sobre o que está acontecendo na área de dados, se inscreva na Newsletter semanal: https://www.datahackers.news/ Conheça nossos comentaristas do Data Hackers News: Monique Femme Links mencionados: Breaking Data Hackers - com a Snowflake Vagas no BeesDemais canais do Data Hackers: Site Linkedin Instagram Tik Tok You Tube
 talk-data.com
talk-data.com
Topic
LLM
Large Language Models (LLM)
1405
tagged
Activity Trend
Top Events
Summary In this episode of the Data Engineering Podcast we welcome back Nick Schrock, CTO and founder of Dagster Labs, to discuss the evolving landscape of data engineering in the age of AI. As AI begins to impact data platforms and the role of data engineers, Nick shares his insights on how it will ultimately enhance productivity and expand software engineering's scope. He delves into the current state of AI adoption, the importance of maintaining core data engineering principles, and the need for human oversight when leveraging AI tools effectively. Nick also introduces Dagster's new components feature, designed to modularize and standardize data transformation processes, making it easier for teams to collaborate and integrate AI into their workflows. Join in to explore the future of data engineering, the potential for AI to abstract away complexity, and the importance of open standards in preventing walled gardens in the tech industry.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementThis episode is brought to you by Coresignal, your go-to source for high-quality public web data to power best-in-class AI products. Instead of spending time collecting, cleaning, and enriching data in-house, use ready-made multi-source B2B data that can be smoothly integrated into your systems via APIs or as datasets. With over 3 billion data records from 15+ online sources, Coresignal delivers high-quality data on companies, employees, and jobs. It is powering decision-making for more than 700 companies across AI, investment, HR tech, sales tech, and market intelligence industries. A founding member of the Ethical Web Data Collection Initiative, Coresignal stands out not only for its data quality but also for its commitment to responsible data collection practices. Recognized as the top data provider by Datarade for two consecutive years, Coresignal is the go-to partner for those who need fresh, accurate, and ethically sourced B2B data at scale. Discover how Coresignal's data can enhance your AI platforms. Visit dataengineeringpodcast.com/coresignal to start your free 14-day trial. Data migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details. This is a pharmaceutical Ad for Soda Data Quality. Do you suffer from chronic dashboard distrust? Are broken pipelines and silent schema changes wreaking havoc on your analytics? You may be experiencing symptoms of Undiagnosed Data Quality Syndrome — also known as UDQS. Ask your data team about Soda. With Soda Metrics Observability, you can track the health of your KPIs and metrics across the business — automatically detecting anomalies before your CEO does. It’s 70% more accurate than industry benchmarks, and the fastest in the category, analyzing 1.1 billion rows in just 64 seconds. And with Collaborative Data Contracts, engineers and business can finally agree on what “done” looks like — so you can stop fighting over column names, and start trusting your data again.Whether you’re a data engineer, analytics lead, or just someone who cries when a dashboard flatlines, Soda may be right for you. Side effects of implementing Soda may include: Increased trust in your metrics, reduced late-night Slack emergencies, spontaneous high-fives across departments, fewer meetings and less back-and-forth with business stakeholders, and in rare cases, a newfound love of data. Sign up today to get a chance to win a $1000+ custom mechanical keyboard. Visit dataengineeringpodcast.com/soda to sign up and follow Soda’s launch week. It starts June 9th.Your host is Tobias Macey and today I'm interviewing Nick Schrock about lowering the barrier to entry for data platform consumersInterview IntroductionHow did you get involved in the area of data management?Can you start by giving your summary of the impact that the tidal wave of AI has had on data platforms and data teams?For anyone who hasn't heard of Dagster, can you give a quick summary of the project?What are the notable changes in the Dagster project in the past year?What are the ecosystem pressures that have shaped the ways that you think about the features and trajectory of Dagster as a project/product/community?In your recent release you introduced "components", which is a substantial change in how you enable teams to collaborate on data problems. What was the motivating factor in that work and how does it change the ways that organizations engage with their data?tension between being flexible and extensible vs. opinionated and constrainedincreased dependency on orchestration with LLM use casesreducing the barrier to contribution for data platform/pipelinesbringing application engineers into the mixchallenges of meeting users/teams where they are (languages, platform investments, etc.)What are the most interesting, innovative, or unexpected ways that you have seen teams applying the Components pattern?What are the most interesting, unexpected, or challenging lessons that you have learned while working on the latest iterations of Dagster?When is Dagster the wrong choice?What do you have planned for the future of Dagster?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Links Dagster+ EpisodeDagster Components Slide DeckThe Rise Of Medium CodeLakehouse ArchitectureIcebergDagster ComponentsPydantic ModelsKubernetesDagster PipesRuby on RailsdbtSlingFivetranTemporalMCP == Model Context ProtocolThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Top tech companies have utilized graphs to power everything, from fraud detection systems to recommendation engines, and they are now finding their way into use cases across industries. This session will introduce the concept of graph analytics and the algorithms used to find hidden insights in data that enhance decision making, with context as king. Additionally, we will explore how Knowledge Graphs can significantly augment LLMs, particularly in the context of Retrieval Augmented Generation (RAG) systems.
Join award-winning broadcaster and national comedy champion, Adam Spencer to learn how technologies like AI, Cyber Security and ChatGPT are disrupting business and how you can win in this world. In this thought-provoking and funny presentation, Adam will share:
• How Artificial Intelligence will impact every industry and how to harness its potential
• The crucial role every worker plays in your cyber security
• The business potential of holding a supercomputer in your hands
• How to keep up if the pace of digital disruption feels overwhelming
Join the JPMorgan Chase Wealth Management RegTech team as they showcase their innovative use of Snowflake to integrate data, analytics and AI into a unified platform for all lines of defense, including controls, risk and compliance. Discover their plans to leverage LLM capabilities through Cortex AI to deliver cutting-edge risk and regulatory insights.
Learn best practices that enhance efficiency by 50%, strengthen compliance, mitigate risks and achieve substantial cost savings. Gain valuable insights into proactive risk management and staying ahead of industry trends and challenges. Don't miss this opportunity to explore the future of data-driven compliance and control.

To gain trust in Generative AI applications, a robust observability framework is needed. In this session, we will demonstrate how users can instrument an AI application with Trulens, an open source observability framework, to trace each component of their application and use LLM-as-a-Judge evaluations to identify and improve points of failure. Attendees will learn about best practices in enabling observability in their AI workflows and common feedback functions used for evaluation. We will also explore using the observability framework as a mechanism to compare application versions to determine which version is best fit for production use.
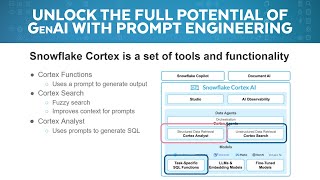
Unlock the full potential of generative AI in Snowflake with hands-on prompt engineering! In this live demo, we'll build and refine prompts from scratch, showcasing how to harness LLM-powered features like Cortex Analyst, Document AI and Cortex functions. Attendees will see real-time development, practical use cases and best practices to get the most out of Snowflake’s AI capabilities — whether for extracting insights, automating workflows or enhancing data pipelines with AI-driven intelligence.
How does a lean data science team at Lottery Corporation manage to avoid the common pitfall of AI/ML being stuck in the lab, have 90% of their models in production and drive substantial business outcomes? Join Dr. Chris Hillman and Stewart Campbell to learn how the current programmes of models are built for success, driving risk reduction, anomaly detection and better customer retention at scale. Then, hear about their plans to use LLM, RAG and agentic AI to drive hyper personalisation, business productivity and better investment decisions.
In this session, we will explore cost transformative vendors such as DeepSeek and MistralAI’s impact on AI development, highlighting the potential to enhance enterprise innovation at a price/performance that is unprecedented. Data, analytics & AI leaders can bring their questions on how they can capitalize on new training and inferencing paradigms in AI, the future of AI model development and the impact of reasoning models on a more autonomous future in AI.
In this episode, Conor recommends some podcast episodes on AI and LLMs. Link to Episode 238 on WebsiteDiscuss this episode, leave a comment, or ask a question (on GitHub)Socials ADSP: The Podcast: TwitterConor Hoekstra: Twitter | BlueSky | MastodonShow Notes Date Generated: 2025-06-11 Date Released: 2025-06-13 ChangeLog: Steve Yegge on productive vibe coding, the death of the IDE, babysitting a fleet of AI coding agentsOxide and Friends 6/2/2025 -- AI Discourse with Steve KlabnikFallthrough: A Discourse on AI DiscourseThe Death of the Junior Developer - Steve YeggeI am disappointed in the AI discourse - Steve KlabnikIntro Song Info Miss You by Sarah Jansen https://soundcloud.com/sarahjansenmusic Creative Commons — Attribution 3.0 Unported — CC BY 3.0 Free Download / Stream: http://bit.ly/l-miss-you Music promoted by Audio Library https://youtu.be/iYYxnasvfx8

Is your AI evaluation process holding back your system's true potential? Many organizations struggle with improving GenAI quality because they don't know how to measure it effectively. This research session covers the principles of GenAI evaluation, offers a framework for measuring what truly matters, and demonstrates implementation using Databricks.Key Takeaways:-Practical approaches for establishing reliable metrics for subjective evaluations-Techniques for calibrating LLM judges to enable cost-effective, scalable assessment-Actionable frameworks for evaluation systems that evolve with your AI capabilitiesWhether you're developing models, implementing AI solutions, or leading technical teams, this session will equip you to define meaningful quality metrics for your specific use cases and build evaluation systems that expose what's working and what isn't, transforming AI guesswork into measurable success.

Taxonomy generation is a challenge across industries such as retail, manufacturing and e-commerce. Incomplete or inconsistent taxonomies can lead to fragmented data insights, missed monetization opportunities and stalled revenue growth. In this session, we will explore a modern approach to solving this problem by leveraging Databricks platform to build a scalable compound AI architecture for automated taxonomy generation. The first half of the session will walk you through the business significance and implications of taxonomy, followed by a technical deep dive in building an architecture for taxonomy implementation on the Databricks platform using a compound AI architecture. We will walk attendees through the anatomy of taxonomy generation, showcasing an innovative solution that combines multimodal and text-based LLMs, internal data sources and external API calls. This ensemble approach ensures more accurate, comprehensive and adaptable taxonomies that align with business needs.

In enterprise AI, Evaluation-Driven Development (EDD) ensures reliable, efficient systems by embedding continuous assessment and improvement into the AI development lifecycle. High-quality evaluation datasets are created using techniques like document analysis, synthetic data generation via Mosaic AI’s synthetic data generation API, SME validation, and relevance filtering, reducing manual effort and accelerating workflows. EDD focuses on metrics such as context relevance, groundedness, and response accuracy to identify and address issues like retrieval errors or model limitations. Custom LLM judges, tailored to domain-specific needs like PII detection or tone assessment, enhance evaluations. By leveraging tools like Mosaic AI Agent Framework and Agent Evaluation, MLflow, EDD automates data tracking, streamlines workflows, and quantifies improvements, transforming AI development for delivering scalable, high-performing systems that drive measurable organizational value.
LLM agents often drift into failure when prompts, retrieval, external data, and policies interact in unpredictable ways. This technical session introduces a repeatable, metric-driven framework for detecting, diagnosing, and correcting these undesirable behaviors in agentic systems at production scale. We demonstrate how to instrument the agent loop with fine-grained signals—tool-selection quality, error rates, action progression, latency, and domain-specific metrics—and send them into an evaluation layer (e.g. Galileo). This telemetry enables a virtuous cycle of system improvement. We present a practical example of a stock-trading system and show how brittle retrieval and faulty business logic cause undesirable behavior. We refactor prompts, adjust the retrieval pipeline—verifying recovery through improved metrics. Attendees will learn how to: add observability with minimal code change, pinpoint root causes via tracing, and drive continuous, metric-validated improvement.

While Databricks powers your data lakehouse, DataHub delivers the critical context layer connecting your entire ecosystem. We'll demonstrate how DataHub extends Unity Catalog to provide comprehensive metadata intelligence across platforms. DataHub's real-time platform:Cut AI model time-to-market with our unified REST and GraphQL APIs that ensure models train on reliable and compliant data from across platforms, with complete lineage trackingDecrease data incidents by 60% using our event-driven architecture that instantly propagates changes across systems*Transform data discovery from days to minutes with AI-powered search and natural language interfaces.Leaders use DataHub to transform Databricks data into integrated insights that drive business value. See our demo of syncback technology—detecting sensitive data and enforcing Databricks access controls automatically—plus our AI assistant that enhances' LLMs with cross-platform metadata.

Imagine performing complex regulatory checks in minutes instead of days. We made this a reality using GenAI on the Databricks Data Intelligence Platform. Join us for a deep dive into our journey from POC to a production-ready AI audit tool. Discover how we automated thousands of legal requirement checks in annual reports with remarkable speed and accuracy. Learn our blueprint for: High-Performance AI: Building a scalable, >90% accurate AI system with an optimized RAG pipeline that auditors praise. Robust Productionization: Achieving secure, governed deployment using Unity Catalog, MLflow, LLM-based evaluation, and MLOps best practices. This session provides actionable insights for deploying impactful, compliant GenAI in the enterprise.

Dive into the latest Llama 4 models. See for yourself how to unleash the power of Llama models and achieve next level performance with our curated set of practical tools, techniques and recipes. Join us as we dive into the world of Llama models, exploring their capabilities, developer tools, and exciting use cases. Discover how these innovative models are transforming industries and improving performance in real-world applications.

The demand for data engineering keeps growing, but data teams are bored by repetitive tasks, stumped by growing complexity and endlessly harassed by an unrelenting need for speed. What if AI could take the heavy lifting off your hands? What if we make the move away from code-generation and into config-generation — how much more could we achieve? In this session, we’ll explore how AI is revolutionizing data engineering, turning pain points into innovation. Whether you’re grappling with manual schema generation or struggling to ensure data quality, this session offers practical solutions to help you work smarter, not harder. You’ll walk away with a good idea of where AI is going to disrupt the data engineering workload, some good tips around how to accelerate your own workflows and an impending sense of doom around the future of the industry!

Matei is a legend of open source: he started the Apache Spark project in 2009, co-founded Databricks, and worked on other widely used data and AI software, including MLflow, Delta Lake, and Dolly. His most recent research is about combining large language models (LLMs) with external data sources, such as search systems, and improving their efficiency and result quality. This will be a conversation coverering the latest and greatest of UC, Data Intelligence, AI Governance, and more.

Go beyond the user interface and explore the cutting-edge technology driving AI/BI Genie. This session breaks down the AI/BI Genie architecture, showcasing how LLMs, retrieval-augmented generation (RAG) and finely tuned knowledge bases work together to deliver fast, accurate responses. We’ll also explore how AI agents orchestrate workflows, optimize query performance and continuously refine their understanding. Ideal for those who want to geek out about the tech stack behind Genie, this session offers a rare look at the magic under the hood.