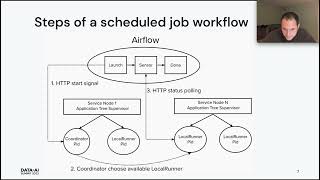
AI for enterprises, particularly in the era of GenAI, requires rapid experimentation and the ability to productionize models and agents quickly and at scale. Compliance, resilience and commercial flexibility drive the need to serve models across regions. As cloud providers struggle with rising demand for GPUs in environments, VM shortages have become commonplace, and add to the pressure of general cloud outages. Enterprises that can quickly leverage GPU capacity in other cloud regions will be better equipped to capitalize on the promise of AI, while staying flexible to serve distinct user bases and complying with regulations. In this presentation we will show and discuss how to implement AI deployments across cloud regions, deploying a model across regions and using a load balancer to determine where to best route a user request.