Securing Databricks on AWS Using Private Link
Minimizing data transfers over the public internet is among the top priorities for organizations of any size, both for security and cost reasons. Modern cloud-native data analytics platforms need to support deployment architectures that meet this objective. For Databricks on AWS such an architecture is realized thanks to AWS PrivateLink, which allows computing resources deployed on different virtual private networks and different AWS accounts to communicate securely without ever crossing the public internet.
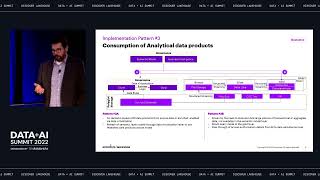
In this session, we want to provide a brief introduction to AWS Private Link and its main use cases in the context of a Databricks deployment: securing communications between control and data plane and securely connecting to the Databricks Web UI. We will then provide step-by-step walkthrough of the steps required in setting up PrivateLink connections with a Databricks deployment and demonstrate how to automate that process using AWS Cloud Formation or Terraform templates.
In this presentation we will cover the following topics: - Brief Introduction to AWS Private Link - How you can use PrivateLink to secure your AWS Databricks deployment - Step-by-step walkthrough of how to set up Private Link - How to automate and scale the setup using AWS CloudFormation or Terraform
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/