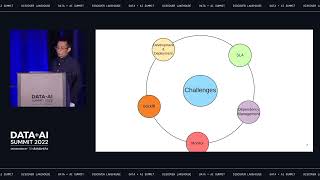
Microservices is an increasingly popular architecture much loved by application teams, for it allows services to be developed and scaled independently. Data teams, though, often need a centralized repository where all data from different services come together to join and aggregate. The data platform can serve as a single source of company facts, enable near real time analytics, and secure sharing of massive data sets across clouds.
A viable microservices ingestion pattern is Change Data Capture, using AWS Database Migration Services or Debezium. CDC proves to be a scalable solution ideal for stable platforms, but it has several challenges for evolving services: Frequent schema changes, complex, unsupported DDL during migration, and automated deployments are but a few. An event streaming architecture can address these challenges.
Confluent, for example, provides a schema registry service where all services can register their event schemas. Schema registration helps with verifying that the events are being published based on the agreed contracts between data producers and consumers. It also provides a separation between internal service logic and the data consumed downstream. The services write their events to Kafka using the registered schemas with a specific topic based on the type of the event.
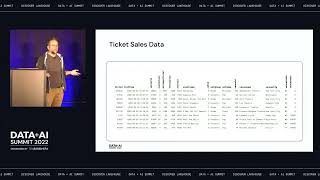
Data teams can leverage Spark jobs to ingest Kafka topics into Bronze tables in the Delta Lake. On ingestion, the registered schema from schema registry is used to validate the schema based on the provided version. A merge operation is sometimes called to translate events into final states of the records per business requirements.
Data teams can take advantage of Delta Live Tables on streaming datasets to produce Silver and Gold tables in near real time. Each input data source also has a set of expectations to ensure data quality and business rules. The pipeline allows Engineering and Analytics to collaborate by mixing Python and SQL. The refined data sets are then fed into Auto ML for discovery and baseline modeling.
To expose Gold tables to more consumers, especially non spark users across clouds, data teams can implement Delta Sharing. Recipients can accesses Silver tables from a different cloud and build their own analytics data sets. Analytics teams can also access Gold tables via pandas Delta Sharing client and BI tools.
Connect with us:
Website: https://databricks.com
Facebook: https://www.facebook.com/databricksinc
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/data...
Instagram: https://www.instagram.com/databricksinc/