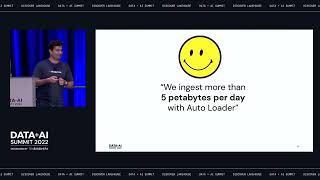
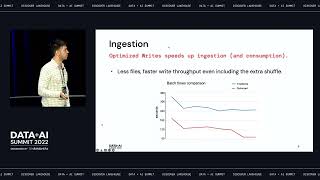
Graph-based stream processing
2022-07-19
Watch
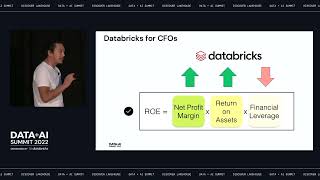
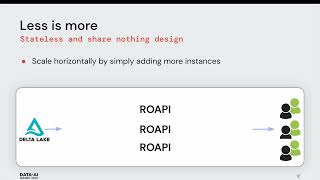
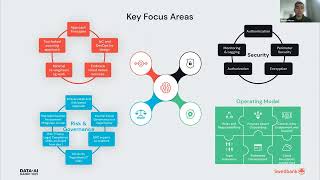
The understanding of complex relationships and interdependencies between different data points is crucial to many decision-making processes.
Graph analytics have found their way into every major industry, from marketing and financial services to transportation. Fraud detection, recommendation engines and process optimization are some of the use cases where real-time decisions are mission-critical, and the underlying domain can be easily modeled as a graph.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/