Competitive advantage hinges on predictive insights generated from AI! Build powerful data-driven
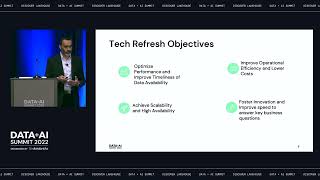
AI is central to unlocking competitive advantage. However data science teams don’t have access to a consistent level of high-quality data required to build AI & ML data applications.
Instead data scientists spend 80% of their time collecting, cleaning & preparing the data for analysis rather than building AI-data applications.
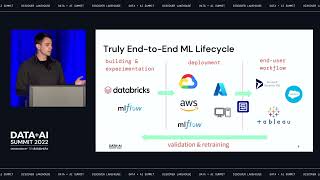
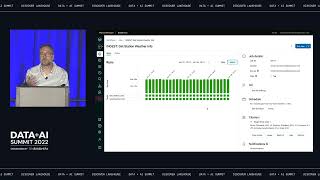
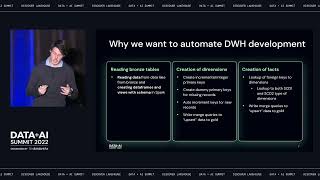
During this talk Snowplow introduces the concept of data creation. Create & deploy high-quality & predictive behavioral data in real-time to Databricks.
Learn how being equipped with AI-ready data in Databricks allows data science teams to focus on building AI data applications rather than data wrangling—dramatically accelerating the pace of data projects & improving model performance & managing data governance. - How to execute more AI & data intensive applications in production using Databricks & Snowplow - How to execute on each AI & data intensive application faster thanks to pre-validated & predictive data - How data creation can solve for data governance
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/