
 talk-data.com
talk-data.com
Topic
AI/ML
Artificial Intelligence/Machine Learning
data_science
algorithms
predictive_analytics
9014
tagged
Activity Trend
1532
peak/qtr
2020-Q1
2026-Q1
Top Events
Google Cloud Next '25
761
Microsoft Ignite 2025
699
Google Cloud Next '24
553
Data + AI Summit 2025
425
O'Reilly Data Science Books
333
Databricks DATA + AI Summit 2023
287
Data Engineering Podcast
271
O'Reilly Data Engineering Books
240
DataFramed
239
Making Data Simple
223
AWS re:Invent 2024
223
DATA MINER Big Data Europe Conference 2020
215
Here we explore how data science is revolutionizing our understanding of protein structures, with a special focus on the exciting developments in protein folding and evolution. We’re joined by two experts in the field: Philip Bourne, the founding dean of the UVA School of Data Science, and Cam Mura, a biomolecular data scientist. From new tools like DeepUrfold to the future of biomedical applications, Bourne and Mura provide a unique look into how cutting-edge technology is transforming the world of molecular biology.
Supported by Our Partners • Graphite — The AI developer productivity platform. • Sentry — Error and performance monitoring for developers. — Reddit’s native mobile apps are more complex than most of us would assume: both the iOS and Android apps are about 2.5 million lines of code, have 500+ screens, and a total of around 200 native iOS and Android engineers work on them. But it wasn’t always like this. In 2021, Reddit started to double down on hiring native mobile engineers, and they quietly rebuilt the Android and iOS apps from the ground up. The team introduced a new tech stack called the “Core Stack” – all the while users remained largely unaware of the changes. What drove this overhaul, and how did the team pull it off? In this episode of The Pragmatic Engineer, I’m joined by three engineers from Reddit’s mobile platform team who led this work: Lauren Darcey (Head of Mobile Platform), Brandon Kobilansky (iOS Platform Lead), and Eric Kuck (Principal Android Engineer). We discuss how the team transitioned to a modern architecture, revamped their testing strategy, improved developer experience – while they also greatly improved the app’s user experience. We also get into: • How Reddit structures its mobile teams—and why iOS and Android remain intentionally separate • The scale of Reddit’s mobile codebase and how it affects compile time • The shift from MVP to MVVM architecture • Why Reddit took a bet on Jetpack Compose, but decided (initially) against using SwiftUI • How automated testing evolved at Reddit • Reddit’s approach to server-driven-mobile-UI • What the mobile platforms team looks for in a new engineering hire • Reddit’s platform team’s culture of experimentation and embracing failure • And much more! If you are interested in large-scale rewrites or native mobile engineering challenges: this episode is for you. — Timestamps (00:00) Intro (02:04) The scale of the Android code base (02:42) The scale of the iOS code base (03:26) What the compile time is for both Android and iOS (05:33) The size of the mobile platform teams (09:00) Why Reddit has so many mobile engineers (11:28) The different types of testing done in the mobile platform (13:20) The benefits and drawbacks of testing (17:00) How Eric, Brandon, and Lauren use AI in their workflows (20:50) Why Reddit grew its mobile teams in 2021 (26:50) Reddit’s modern tech stack, Corestack (28:48) Why Reddit shifted from MVP architecture to MVVM (30:22) The architecture on the iOS side (32:08) The new design system (30:55) The impact of migrating from Rust to GraphQL (38:20) How the backend drove the GraphQL migration and why it was worth the pain (43:17) Why the iOS team is replacing SliceKit with SwiftUI (48:08) Why the Android team took a bet on Compose (51:25) How teams experiment with server-driven UI—when it worked, and when it did not (54:30) Why server-driven UI isn’t taking off, and why Lauren still thinks it could work (59:25) The ways that Reddit’s modernization has paid off, both in DevX and UX (1:07:15) The overall modernization philosophy; fixing pain points (1:09:10) What the mobile platforms team looks for in a new engineering hire (1:16:00) Why startups may be the best place to get experience (1:17:00) Why platform teams need to feel safe to fail (1:20:30) Rapid fire round — The Pragmatic Engineer deepdives relevant for this episode: • The platform and program split at Uber • Why and how Notion went native on iOS and Android • Paying down tech debt • Cross-platform mobile development — See the transcript and other references from the episode at https://newsletter.pragmaticengineer.com/podcast — Production and marketing by https://penname.co/. For inquiries about sponsoring the podcast, email [email protected].
Get full access to The Pragmatic Engineer at newsletter.pragmaticengineer.com/subscribe
Send us a text 🎙️ Ruchir Puri (Part 1): From Prompt Engineering to Agentic AI Guest: Ruchir Puri, Chief Scientist at IBM Research 📍 Website: ibm.com/watsonx 🎧 Host: Al Martin, Worldwide VP, Technical Sales, IBM 📨 Want to be a guest? Email us at [email protected] 👤 About the Guest Dr. Ruchir Puri is IBM Fellow, Chief Scientist of IBM Research, and one of IBM’s most prolific inventors. With over 70 patents and a lead architect behind IBM’s AI breakthroughs including Watson and watsonx, Ruchir is a globally respected authority on AI, chip design, and scalable compute. He’s led groundbreaking work from Deep Blue to Agentic AI and is shaping how AI will drive the next era of enterprise transformation. 🧠 What’s Inside This Episode This episode is a masterclass in where AI is headed. Ruchir takes us on a journey from the fading relevance of prompt engineering to the rise of agentic AI systems that think, plan, execute, and reflect. You’ll hear his candid views on inference at scale, memory in systems, and why 2025 is the year of agents. ⏱️ Chapters & Timing 01:22 – Hints for the IBM THINK Conference Sneak peek into what’s coming at THINK — and what not to miss.04:09 – What Drives Ruchir From childhood curiosity to global impact. How does a mind like his stay inspired?10:00 – Where Are We Now: Feedback Systems Why the “training is done” mindset is outdated and how feedback loops change the game.12:21 – Prompt Engineering Gone! Hot take alert! Ruchir declares the death of prompt engineering — and what replaces it.13:39 – Inference Scaling How scaling inference (not just training) is the next AI frontier.16:26 – Systems with Memory Why “forgetting” systems are failing us — and how memory transforms intelligence.17:56 – Agentic AI: Think, Plan, Act, Execute, Observe, Reflect A full walkthrough of what makes AI “agentic” and where we’re headed next.21:02 – Future of Work and MCP (Multi-Contextual Personas) AI in the workplace isn’t about job replacement — it’s about augmentation.23:45 – 2025: The Year of Agents Why this year will be the breakout moment for agents in enterprise AI.23:58 – The Open Ecosystem Open-source meets enterprise grade. Ruchir breaks it down.26:38 – Agentic AI Leader Final thoughts on leadership in AI and how to stay ahead.💬 Quotes to Remember “Prompt engineering is dead. It’s like writing assembler. You needed it at first. But not anymore.”“The true intelligence lies in systems that can remember — not just respond.”“We’re heading into an era where your agent will know you better than your coworkers do.”🔥 Why You Should Listen If you want a front-row seat to the future of AI — especially in enterprise environments — this is it. Ruchir combines deep tech insights with strategic vision, all while keeping it practical and human. 📩 Subscribe & Stay Ahead Follow us on your favorite platform and never miss an episode that helps you lead with tech — simply. Want to be featured as a guest on Making Data Simple? Reach out to us at [email protected] and tell us why you should be next. The Making Data Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, where we explore trending technologies, business innovation, and leadership ... while keeping it simple & fun.
10-min startup demo in AI Launchpad.
Takeaways Feedback is crucial for growth but often lacking. Visual storytelling can enhance understanding. Long explanations may not be effective in busy environments. Tools like Code to Story can simplify complex ideas. People prefer quick, visual information over lengthy texts. The development process can be messy but rewarding. Understanding your audience's time constraints is key. Visual aids can significantly improve communication. Building something understandable is more important than perfection. Let your work speak for itself through visuals.
Blog that shows you how to do this yourself: https://medium.com/towards-artificial-intelligence/how-to-instantly-explain-your-code-with-visuals-powered-by-gpt-4-bc379985f43f Subscribe to my Substack for updates on the course: https://mukundansankar.substack.com/
10-min startup demo in AI Launchpad.
10-min startup demo in AI Launchpad.
10-min startup demo in AI Launchpad.
10-min startup demo in AI Launchpad.
10-min startup demo in AI Launchpad.

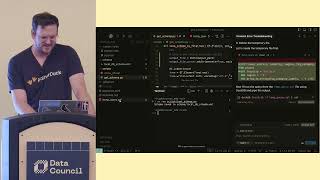
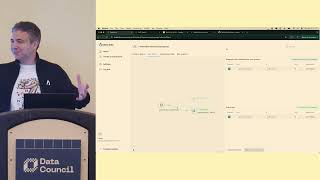

Takeaways Explaining your work is often more challenging than the work itself. Many analysts struggle to communicate their logic and findings. Storytelling is a crucial skill for career advancement in tech. Code2Story was created to help analysts articulate their work better. The tool transforms code into a narrative that is easier to understand. Anyone who writes code can benefit from using Code2Story. The app is not just for engineers but for all who need to explain their work. Storytelling can elevate the perception of your work beyond just numbers. The process of using Code2Story is simple and accessible. This tool represents a shift towards valuing communication in technical fields.
Blog with Full code: https://medium.com/towards-artificial-intelligence/i-built-an-ai-that-turns-side-projects-into-stories-that-get-you-hired-f51cac9e1a32
Megan Bowers took an unconventional path to break into the data world. Starting from a self-guided Data Science Bootcamp, she shared her journey through blogging and gained millions of views, and then BOOM! Job offers and monetization opportunities flooded. This is her story. 📌 Interested in blogging for my publication? Get on this interest list: https://tally.so/r/3l4xQW 💌 Join 10k+ aspiring data analysts & get my tips in your inbox weekly 👉 https://www.datacareerjumpstart.com/newsletter 🆘 Feeling stuck in your data journey? Come to my next free "How to Land Your First Data Job" training 👉 https://www.datacareerjumpstart.com/training 👩💻 Want to land a data job in less than 90 days? 👉 https://www.datacareerjumpstart.com/daa 👔 Ace The Interview with Confidence 👉 https://www.datacareerjumpstart.com/interviewsimulator ⌚ TIMESTAMPS 00:00 - Introduction 03:28 - Gaining traction and recognition through blogging. 07:08 - Career Growth and transition to Alteryx. 14:18 - Leveraging and advertising your domain expertise. 19:25 - What is a Data Journalist? 22:21 - Writing content. 24:29 - What is Alteryx? 🔗 CONNECT WITH MEGAN 🎥 YouTube Podcast Channel: https://www.youtube.com/playlist?list=PLfSLx4WE4q501UZjL3Hx-DiS4zyeePEN2 🤝 LinkedIn: https://www.linkedin.com/in/megandibble1/ 📸 Instagram: https://www.instagram.com/alteryx/ 💻 Alteryx Website: https://www.alteryx.com/ 🔗 CONNECT WITH AVERY 🎥 YouTube Channel: https://www.youtube.com/@averysmith 🤝 LinkedIn: https://www.linkedin.com/in/averyjsmith/ 📸 Instagram: https://instagram.com/datacareerjumpstart 🎵 TikTok: https://www.tiktok.com/@verydata 💻 Website: https://www.datacareerjumpstart.com/ Mentioned in this episode: Join the last cohort of 2025! The LAST cohort of The Data Analytics Accelerator for 2025 kicks off on Monday, December 8th and enrollment is officially open!
To celebrate the end of the year, we’re running a special End-of-Year Sale, where you’ll get: ✅ A discount on your enrollment 🎁 6 bonus gifts, including job listings, interview prep, AI tools + more
If your goal is to land a data job in 2026, this is your chance to get ahead of the competition and start strong.
👉 Join the December Cohort & Claim Your Bonuses: https://DataCareerJumpstart.com/daa https://www.datacareerjumpstart.com/daa
We live in an era where data is abundant, yet making sense of it is harder than ever. The best insights often go unnoticed—not because they lack value, but because they lack a compelling story. Simply presenting numbers isn’t enough; the way we shape and frame data determines whether it sparks action or fades into the background. Crafting a strong data story means knowing your audience, structuring your insights around a clear problem, goal, action, and impact, and ensuring your narrative is not just persuasive, but ethical. So how do we bridge the gap between information and understanding? How can we tailor data stories to resonate with decision-makers, stakeholders, and the public in ways that drive meaningful change? Kat Greenbrook is a Data Storyteller from Aotearoa, New Zealand. She is a consultant, workshop facilitator, industry speaker, and founder of the data storytelling company Rogue Penguin Ltd. With a unique blend of science, business, and design, she empowers data professionals to communicate data effectively through storytelling. Kat’s book, The Data Storyteller's Handbook, is the result of hundreds of data storytelling workshops, along with years of refining content and techniques. It represents the very best of what she has learned and witnessed. In the episode, Richie and Kat explore the art of data storytelling, the importance of audience-tailored narratives, the problem-goal-action-impact framework, ethical storytelling, and much more. Links Mentioned in the Show: Kat’s Book: The Data Storyteller's HandbookConnect with KatCourse: Data Storytelling ConceptsRelated Episode: Data Storytelling and Visualization with Lea Pica from Present Beyond MeasureRewatch sessions from RADAR: Skills Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
Summary In this episode of the Data Engineering Podcast Viktor Kessler, co-founder of Vakmo, talks about the architectural patterns in the lake house enabled by a fast and feature-rich Iceberg catalog. Viktor shares his journey from data warehouses to developing the open-source project, Lakekeeper, an Apache Iceberg REST catalog written in Rust that facilitates building lake houses with essential components like storage, compute, and catalog management. He discusses the importance of metadata in making data actionable, the evolution of data catalogs, and the challenges and innovations in the space, including integration with OpenFGA for fine-grained access control and managing data across formats and compute engines.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Your host is Tobias Macey and today I'm interviewing Viktor Kessler about architectural patterns in the lakehouse that are unlocked by a fast and feature-rich Iceberg catalogInterview IntroductionHow did you get involved in the area of data management?Can you describe what LakeKeeper is and the story behind it? What is the core of the problem that you are addressing?There has been a lot of activity in the catalog space recently. What are the driving forces that have highlighted the need for a better metadata catalog in the data lake/distributed data ecosystem?How would you characterize the feature sets/problem spaces that different entrants are focused on addressing?Iceberg as a table format has gained a lot of attention and adoption across the data ecosystem. The REST catalog format has opened the door for numerous implementations. What are the opportunities for innovation and improving user experience in that space?What is the role of the catalog in managing security and governance? (AuthZ, auditing, etc.)What are the channels for propagating identity and permissions to compute engines? (how do you avoid head-scratching about permission denied situations)Can you describe how LakeKeeper is implemented?How have the design and goals of the project changed since you first started working on it?For someone who has an existing set of Iceberg tables and catalog, what does the migration process look like?What new workflows or capabilities does LakeKeeper enable for data teams using Iceberg tables across one or more compute frameworks?What are the most interesting, innovative, or unexpected ways that you have seen LakeKeeper used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on LakeKeeper?When is LakeKeeper the wrong choice?What do you have planned for the future of LakeKeeper?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links LakeKeeperSAPMicrosoft AccessMicrosoft ExcelApache IcebergPodcast EpisodeIceberg REST CatalogPyIcebergSparkTrinoDremioHive MetastoreHadoopNATSPolarsDuckDBPodcast EpisodeDataFusionAtlanPodcast EpisodeOpen MetadataPodcast EpisodeApache AtlasOpenFGAHudiPodcast EpisodeDelta LakePodcast EpisodeLance Table FormatPodcast EpisodeUnity CatalogPolaris CatalogApache GravitinoPodcast Episode KeycloakOpen Policy Agent (OPA)Apache RangerApache NiFiThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA

This book covers the science of measuring the invisible building blocks of thought processes that are useful for understanding humans, including technology users, media consumers, and consumers of goods and services. It provides: An explanation of what self-report measurement entails for beginners; A clear set of assumptions needed in order for self-report measures to yield valuable information; A mindset that needs to be adopted when using self-report measurement in the contexts of surveys and experiments; Guidance for extracting opinion from social media text content and integrating AI; A roadmap for quantifying the errors associated with self-report measurement.