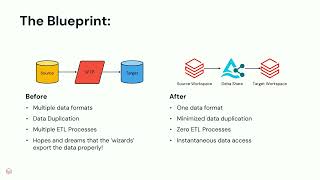
Addepar possesses an enormous private investment data set with 40% of the $7T assets on the platform allocated to alternatives. Leveraging the Addepar Data Lakehouse (ADL), built on Databricks, we have built a scalable data pipeline that assesses millions of private fund investment cash flows and translates it to a private fund benchmarks data offering. Investors on the Addepar platform can leverage this data seamlessly integrated against their portfolio investments and obtain actionable investment insights. At a high-level, this data offering consists of an extensive data aggregation, filtering, and construction logic that dynamically updates for clients through the Databricks job workflows. This derived dataset has gone through several iterations with investment strategists and academics that leveraged delta shared tables. Irrespective of the data source, the data pipeline coalesces all relevant cash flow activity against a unique identifier before constructing the benchmarks.