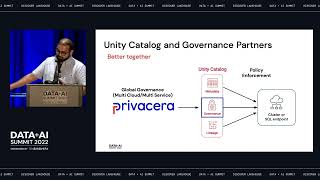
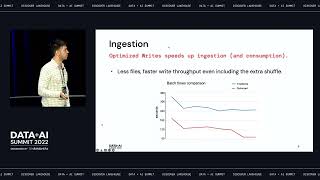
Data is no longer considered an asset to be protected within teams, but as an asset to be democratized and made available to everyone in the organization in a secure and governed manner. The Data Mesh is an evolving data architecture pattern that helps organizations in breaking down data silos and providing agility to respond to market changes quickly with decentralized data ownership and centralized governance and security.
This talk will provide details and demonstrate how to use Databricks Delta Lake with Unity Catalog to implement and operationalize the Data Mesh Architecture pattern. The demo includes LTI Canvas Alcazar solution which helps accelerate the data mesh implementation with Databricks.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/