Deliver Faster Decision Intelligence From Your Lakehouse
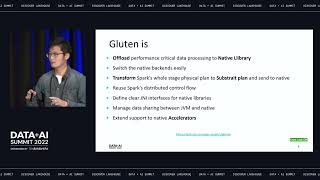
Accelerate the path from data to decisions with the the Tellius AI-driven Decision Intelligence platform powered by Databricks Delta Lake. Empower business users and data teams to analyze data residing in the Delta Lake to understand what is happening in their business, uncover the reasons why metrics change, and get recommendations on how to impact outcomes. Learn how organizations derive value from Delta Lakehouse with a modern analytics experience that unifies guided insights, natural language search, and automated machine learning to speed up data-driven decision making at cloud scale.
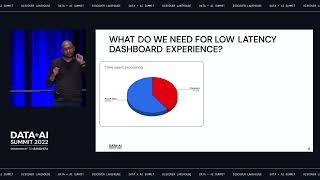
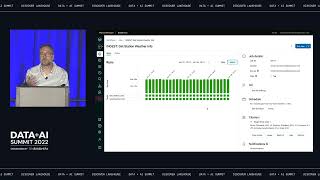
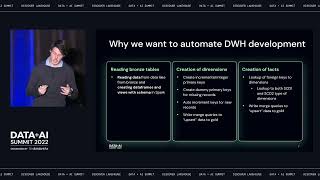
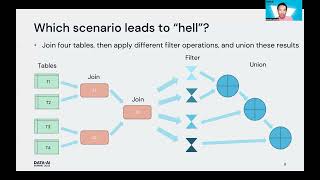
In this session, we will showcase how customers: - Discover changes in KPIs and investigate the reasons why metrics change with AI-powered automated analysis - Empower business users and data analysts to iteratively explore data to identify trend drivers, uncover new customer segments, and surface hidden patterns in data - Simplify and speed-up analysis from massive datasets on Databrick Delta lake
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/