Swedbank is the largest bank in Sweden & third largest in Nordics. They have about 7-8M customers across retail, mortgage , and investment (pensions). One of the key drivers for the bank was to look at data across all silos and build analytics to drive their ML models - they couldn’t. That’s when Swedbank made a strategic decision to go to the cloud and make bets on Databricks, Immuta, and Azure.
-Enterprise analytics in cloud is an initiative to move Swedbanks on-premise Hadoop based data lake into the cloud to provide improved analytical capabilities at scale. The strategic goals of the “Analytics Data Lake” are:
-Advanced analytics: Improve analytical capabilities in terms of functionality, reduce analytics time to market and better predictive modelling
-A Catalyst for Sharing Data: Make data Visible, Accessible, Understandable, Linked, and Trusted
Technical advancements: Future proof with ability to add new tools/libraries, support for 3rd party solutions for Deep Learning/AI
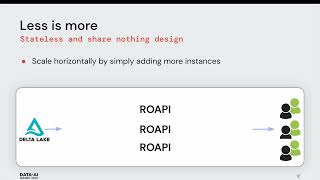
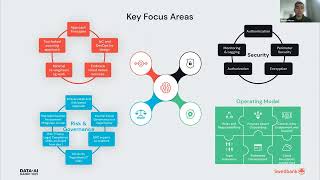
To achieve these goals, Swedbank had to migrate existing capabilities and application services to Azure Databricks & implement Immuta as its unified access control plane. A “data discovery” space was created for data scientists to be able to come & scan (new) data, develop, train & operationalise ML models. To meet these goals Swedbank requires dynamic and granular data access controls to both mitigate data exposure (due to compromised accounts, attackers monitoring a network, and other threats) while empowering users via self-service data discovery & analytics. Protection of sensitive data is key to enable Swedbank to support key financial services use cases.
The presentation will focus on this journey, calling out key technical challenges, learning & benefits observed.
Connect with us:
Website: https://databricks.com
Facebook: https://www.facebook.com/databricksinc
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/data...
Instagram: https://www.instagram.com/databricksinc/