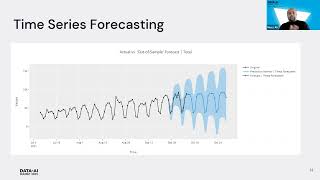
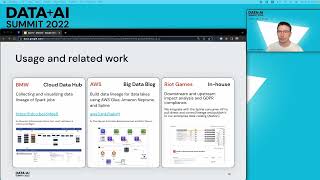
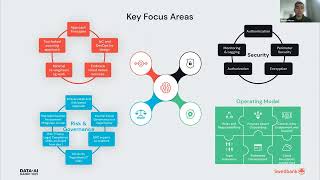
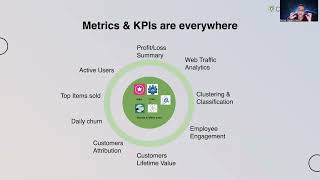
Think for a moment about an ML pipeline that you have created. Was it tedious to write? Did you have to familiarize yourself with technology outside your normal domain? Did you find many bugs? Did you give up with a “good enough” solution? Even simple ML pipelines are tedious. Complex ML pipelines make teams that include Data Engineers and ML Engineers still end up with delays and bugs. Okta’s FIG (Feature Infrastructure Generator) simplifies this with a configuration language for Data Scientists that produces scalable and correct ML pipelines, even highly complex ones. FIG is “just a library” in the sense that you can PIP install it. Once installed, FIG will configure your AWS account, creating ETL jobs, workflows, and ML training and scoring jobs. Data Scientists then use FIG’s configuration language to specify features and model integrations. With a single function call, FIG will run an ML pipeline to generate feature data, train models, and create scoring data. Feature generation is performed in a scalable, efficient, and temporally correct manner. Model training artifacts and scoring are automatically labeled and traced. This greatly simplifies the ML prototyping experience. Once it is time to productionize a model, FIG is able to use the same configuration to coordinate with Okta’s deployment infrastructure to configure production AWS accounts, register build and model artifacts, and setup monitoring. This talk will show a demo of using FIG in the development of Okta’s next generation security infrastructure. The demo includes a walkthrough of the configuration language and how that is translated into AWS during a prototyping session. The demo will also briefly cover how FIG interacts with Okta’s deployment system to make productionization seamless.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/