Le moteur de recherche est au cœur de l’expérience utilisateur. Mais comment passer d’une recherche « classique » basée sur des mots-clés à une recherche sémantique capable de comprendre réellement les intentions ? Dans cette session, l’équipe The Fork partagera leur projet d’évolution vers une recherche augmentée par l’IA. En s’appuyant sur leur stack OpenSearch existante, ils ont ajouté une couche sémantique grâce aux LLM. L’objectif : analyser les requêtes utilisateurs, en extraire les éléments essentiels et les traduire en une recherche sémantique beaucoup plus pertinente. Vous découvrirez les défis rencontrés, les choix d’implémentation et les résultats obtenus dans un cas concret à fort impact utilisateur.
 talk-data.com
talk-data.com
Topic
LLM
Large Language Models (LLM)
nlp
ai
machine_learning
1405
tagged
Activity Trend
158
peak/qtr
2020-Q1
2026-Q2
Top Events
Send us a text This is one of my favorite episodes - it's all about the story! Part 2 of our conversation with Vinca LaFleur, Founding Partner of West Wing Writers. From the power of ideas to the art of delivery, Vinca shares what it takes to write words that resonate — and why every great message starts with meaning. 00:30 Tricks and tips to a presentation04:14 Speech gotchas07:29 Knowing when you have a hit09:39 How much is delivery11:53 GOAT speech Bobby Kennedy in Indianapolis: https://www.youtube.com/watch?v=A2kWIa8wSC014:49 Gettysburg case study17:11 ChatGPT?20:26 Mental cups26:55 West Wing Writers31:51 Chief34:30 Book recommended most Made to Stick: https://www.amazon.com/Made-Stick-Ideas-SurviveOthers/dp/1400064287 Want to be featured as a guest on Making Data Simple? Reach out to us at [email protected] and tell us why you should be next. The Making Data Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, where we explore trending technologies, business innovation, and leadership ... while keeping it simple & fun.
This week, I’m showing you exactly how I used AI agents to fix my job hunt — no hype, just results. I was juggling dozens of job applications, interviews, and follow-ups until I built three small agents that acted like my personal job search team. In this episode, I do a live demo of: A Researcher Agent that finds company insights automaticallyA Writer Agent that drafts personal outreach messagesA Reviewer Agent that polishes tone and clarityTogether, they turned hours of chaos into minutes of clear progress. You’ll see how these agents plan, collaborate, and improve your workflow — and how you can build your own version tonight using just ChatGPT or any LLM platform. By the end, you’ll understand what makes agents powerful: planning, memory, and feedback.
🔗 Connect with Me: Free Email NewsletterWebsite: Data & AI with MukundanGitHub: https://github.com/mukund14Twitter/X: @sankarmukund475LinkedIn: Mukundan SankarYouTube: Subscribe
Ryan Dolley, VP of Product Strategy at GoodData and co-host of Super Data Brothers podcast, joined Yuliia and Dumke to discuss the DBT-Fivetran merger and what it signals about the modern data stack's consolidation phase. After 16 years in BI and analytics, Ryan explains why BI adoption has been stuck at 27% for a decade and why simply adding AI chatbots won't solve it. He argues that at large enterprises, purchasing new software is actually the only viable opportunity to change company culture - not because of the features, but because it forces operational pauses and new ways of working. Ryan shares his take that AI will struggle with BI because LLMs are trained to give emotionally satisfying answers rather than accurate ones. Ryan Dolley linkedin
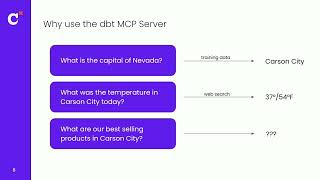
Modern data teams are tasked with bringing AI into the analytics stack in a way that is trustworthy, scalable, and deeply integrated. In this session, we’ll show how the dbt MCP server connects LLMs and agents to structured and governed data to power use cases for development, discovery, and querying.
Brought to You By: • Statsig — The unified platform for flags, analytics, experiments, and more. Something interesting is happening with the latest generation of tech giants. Rather than building advanced experimentation tools themselves, companies like Anthropic, Figma, Notion and a bunch of others… are just using Statsig. Statsig has rebuilt this entire suite of data tools that was available at maybe 10 or 15 giants until now. Check out Statsig. • Linear – The system for modern product development. Linear is just so fast to use – and it enables velocity in product workflows. Companies like Perplexity and OpenAI have already switched over, because simplicity scales. Go ahead and check out Linear and see why it feels like a breeze to use. — What is it really like to be an engineer at Google? In this special deep dive episode, we unpack how engineering at Google actually works. We spent months researching the engineering culture of the search giant, and talked with 20+ current and former Googlers to bring you this deepdive with Elin Nilsson, tech industry researcher for The Pragmatic Engineer and a former Google intern. Google has always been an engineering-driven organization. We talk about its custom stack and tools, the design-doc culture, and the performance and promotion systems that define career growth. We also explore the culture that feels built for engineers: generous perks, a surprisingly light on-call setup often considered the best in the industry, and a deep focus on solving technical problems at scale. If you are thinking about applying to Google or are curious about how the company’s engineering culture has evolved, this episode takes a clear look at what it was like to work at Google in the past versus today, and who is a good fit for today’s Google. Jump to interesting parts: (13:50) Tech stack (1:05:08) Performance reviews (GRAD) (2:07:03) The culture of continuously rewriting things — Timestamps (00:00) Intro (01:44) Stats about Google (11:41) The shared culture across Google (13:50) Tech stack (34:33) Internal developer tools and monorepo (43:17) The downsides of having so many internal tools at Google (45:29) Perks (55:37) Engineering roles (1:02:32) Levels at Google (1:05:08) Performance reviews (GRAD) (1:13:05) Readability (1:16:18) Promotions (1:25:46) Design docs (1:32:30) OKRs (1:44:43) Googlers, Nooglers, ReGooglers (1:57:27) Google Cloud (2:03:49) Internal transfers (2:07:03) Rewrites (2:10:19) Open source (2:14:57) Culture shift (2:31:10) Making the most of Google, as an engineer (2:39:25) Landing a job at Google — The Pragmatic Engineer deepdives relevant for this episode: • Inside Google’s engineering culture • Oncall at Google • Performance calibrations at tech companies • Promotions and tooling at Google • How Kubernetes is built • The man behind the Big Tech comics: Google cartoonist Manu Cornet — Production and marketing by https://penname.co/. For inquiries about sponsoring the podcast, email [email protected].
Get full access to The Pragmatic Engineer at newsletter.pragmaticengineer.com/subscribe
Explore how GANs, VAEs, and LLMs create realistic synthetic test data that preserves statistical properties, discovers edge cases, and maintains privacy.
Explore how GANs, VAEs, and LLMs create realistic synthetic test data that preserves statistical properties, discovers edge cases, and maintains privacy.
Send us a text We're joined by Douwe Kiela, CEO of Contextual.ai and pioneer in RAG research. From deploying AI agents at Fortune 500 companies to shedding light on data privacy and security, Douwe shares his expertise and insights on how to make data simple, effective, and secure. 00:46 Introducing Douwe Kiela 01:37 RAG - Here to Stay or Go? 06:59 LLMs with Context 08:20 Making AI Successful 10:34 Why Contextual AI? 17:18 LLM versus SLMs 20:28 Speed over Perfection 22:07 Hallucinations 26:02 Making AI Easy to Consume 28:50 Defining an Agent 32:53 Reaching Contextual AI 33:14 The Contrarian View 34:37 The Risks of AI 36:53 For Fun
LinkedIn: linkedin.com/in/douwekiela Website: https://contextual.ai/ Want to be featured as a guest on Making Data Simple? Reach out to us at [email protected] and tell us why you should be next. The Making Data Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, where we explore trending technologies, business innovation, and leadership ... while keeping it simple & fun. Want to be featured as a guest on Making Data Simple? Reach out to us at [email protected] and tell us why you should be next. The Making Data Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, where we explore trending technologies, business innovation, and leadership ... while keeping it simple & fun.

by
Nick Brisoux
(Tableau)
,
Russell Christopher
(dbt Labs)
,
Anjan Kundavaram
(Fivetran)
,
Ashley Kramer
(OpenAI)
,
Chris Child
(Snowflake)
The future of AI is here. Join AI and data industry thought leader Ashley Kramer from OpenAI as she shares how AI-powered development and intelligent systems act as force multipliers for organizations—and how to confidently embrace these accelerants at scale. In the second half of the keynote, she'll be joined by a panel of product leaders from across the data stack for a discussion on the future of analytics in an AI-driven world and how dbt and ecosystem partners are innovating to rewrite what’s possible: turning yesterday's science fiction into today's reality. For our Coalesce Online attendees, join us on Slack in #coalesce-2025 to stay connected during keynote!
Bilt Rewards turned their dbt project into a natural language interface. By connecting their semantic layer and underlying data warehouse to an LLM, business users and data analysts can ask real business questions and get trusted and creative insights. This session shows how they modeled their data for AI, how they kept accuracy intact, and increased data driven conversations across the business.
Meet Zack Kass – a former Head of Go-to-Market at OpenAI, and gain key insights that will power your testing career.
In this episode, we talked with Aishwarya Jadhav, a machine learning engineer whose career has spanned Morgan Stanley, Tesla, and now Waymo. Aishwarya shares her journey from big data in finance to applied AI in self-driving, gesture understanding, and computer vision. She discusses building an AI guide dog for the visually impaired, contributing to malaria mapping in Africa, and the challenges of deploying safe autonomous systems. We also explore the intersection of computer vision, NLP, and LLMs, and what it takes to break into the self-driving AI industry.TIMECODES00:51 Aishwarya’s career journey from finance to self-driving AI05:45 Building AI guide dog for the visually impaired12:03 Exploring LiDAR, radar, and Tesla’s camera-based approach16:24 Trust, regulation, and challenges in self-driving adoption19:39 Waymo, ride-hailing, and gesture recognition for traffic control24:18 Malaria mapping in Africa and AI for social good29:40 Deployment, safety, and testing in self-driving systems37:00 Transition from NLP to computer vision and deep learning43:37 Reinforcement learning, robotics, and self-driving constraints51:28 Testing processes, evaluations, and staged rollouts for autonomous driving52:53 Can multimodal LLMs be applied to self-driving?55:33 How to get started in self-driving AI careersConnect with Aishwarya- Linkedin - https://www.linkedin.com/in/aishwaryajadhav8/Connect with DataTalks.Club:- Join the community - https://datatalks.club/slack.html- Subscribe to our Google calendar to have all our events in your calendar - https://calendar.google.com/calendar/r?cid=ZjhxaWRqbnEwamhzY3A4ODA5azFlZ2hzNjBAZ3JvdXAuY2FsZW5kYXIuZ29vZ2xlLmNvbQ- Check other upcoming events - https://lu.ma/dtc-events- GitHub: https://github.com/DataTalksClub- LinkedIn - https://www.linkedin.com/company/datatalks-club/ - Twitter - https://twitter.com/DataTalksClub - Website - https://datatalks.club/
In this episode, we talked with Ranjitha Kulkarni, a machine learning engineer with a rich career spanning Microsoft, Dropbox, and now NeuBird AI. Ranjitha shares her journey into ML and NLP, her work building recommendation systems, early AI agents, and cutting-edge LLM-powered products. She offers insights into designing reliable AI systems in the new era of generative AI and agents, and how context engineering and dynamic planning shape the future of AI products.TIMECODES00:00 Career journey and early curiosity04:25 Speech recognition at Microsoft05:52 Recommendation systems and early agents at Dropbox07:44 Joining NewBird AI12:01 Defining agents and LLM orchestration16:11 Agent planning strategies18:23 Agent implementation approaches22:50 Context engineering essentials30:27 RAG evolution in agent systems37:39 RAG vs agent use cases40:30 Dynamic planning in AI assistants43:00 AI productivity tools at Dropbox46:00 Evaluating AI agents53:20 Reliable tool usage challenges58:17 Future of agents in engineering Connect with Ranjitha- Linkedin - https://www.linkedin.com/in/ranjitha-gurunath-kulkarniConnect with DataTalks.Club:- Join the community - https://datatalks.club/slack.html- Subscribe to our Google calendar to have all our events in your calendar - https://calendar.google.com/calendar/r?cid=ZjhxaWRqbnEwamhzY3A4ODA5azFlZ2hzNjBAZ3JvdXAuY2FsZW5kYXIuZ29vZ2xlLmNvbQ- Check other upcoming events - https://lu.ma/dtc-events- GitHub: https://github.com/DataTalksClub- LinkedIn - https://www.linkedin.com/company/datatalks-club/ - Twitter - https://twitter.com/DataTalksClub - Website - https://datatalks.club/

Master Generative AI in software development with hands-on guidance, from coding and debugging to testing and deployment, using GitHub Copilot, Amazon Q Developer, and OpenAI APIs to build scalable, AI-powered applications Key Features Hands-on guidance for mastering AI-powered coding, debugging, and deployment with real-world examples Comprehensive coverage of GenAI concepts, prompt engineering, fine-tuning, and SDLC integration Practical strategies for architecting and scaling production-ready AI-driven applications Book Description Generative AI for Software Developers is your practical guide to mastering AI-powered development and staying ahead in a fast-changing industry. Through a structured, hands-on approach, this book helps you understand, implement, and optimize Generative AI in modern software engineering. From AI-assisted coding, debugging, and documentation to testing, deployment, and system design, it equips you with the skills to integrate AI seamlessly into your workflows. You’ll work with tools such as GitHub Copilot, Amazon Q Developer, and OpenAI APIs while learning strategies for prompt engineering, fine-tuning, and building scalable AI-powered applications. Featuring real-world use cases, best practices, and expert insights, this book bridges the gap between experimenting with AI and production deployment. Whether you’re an aspiring AI developer, experienced engineer, or solutions architect, this guide gives you the clarity, confidence, and tactical knowledge to thrive in the GenAI-driven future of software development. Armed with these insights, you’ll be ready to build, integrate, and scale intelligent solutions that enhance every stage of the software development lifecycle. What you will learn Build a secure GenAI application with expert guidance Understand the fundamentals of GenAI and its applications in software engineering Automate coding tasks with tools like GitHub Copilot, Amazon Q Developer, and OpenAI APIs Apply AI for debugging, testing, documentation, and deployment workflows Get to grips with prompt engineering and fine-tuning techniques to optimize AI outputs Implement best practices for architecting and scaling AI-powered applications Build end-to-end GenAI projects, moving from experimentation to production Who this book is for This book is for software developers, engineers, architects, and tech professionals who want to understand the core concepts of Generative AI and its real-world applications, master AI-driven development workflows to improve efficiency and code quality, and leverage tools like GitHub Copilot, Amazon Q Developer, and OpenAI APIs to automate coding tasks.
Tech talks on AI, GenAI, LLMs and Agent; hands-on experiences on code labs and workshops.
This session will explore why and how Snowflake's unique capabilities are crucial to enable, accelerate and implement industrial IoT use cases like root cause analysis of asset failure, predictive maintenance and quality management. The session will explain the use of specific time series capabilities (e.g. asof joins, CORR & MATCH function), built-in Cortex ML functions (like anomaly detection and forecasting) and LLMs leveraging RAG to accelerate use cases for manufacturing customers.
Está no ar, o Data Hackers News !! Os assuntos mais quentes da semana, com as principais notícias da área de Dados, IA e Tecnologia, que você também encontra na nossa Newsletter semanal, agora no Podcast do Data Hackers !! Aperte o play e ouça agora, o Data Hackers News dessa semana ! Para saber tudo sobre o que está acontecendo na área de dados, se inscreva na Newsletter semanal: https://www.datahackers.news/ Conheça nossos comentaristas do Data Hackers News: Monique Femme Matérias/assuntos comentados: Demais canais do Data Hackers: Site Linkedin Instagram Tik Tok You Tube
You have likely witnessed the hype-cycle around MCP (the Model-Context Protocol) for LLMs. It was heralded as \"the universal interface between LLMs and the world\" but then faded into the background as attention shifted towards AI Agents. Yet, the background of your AI app is exactly where an MCP should be, and in this talk we cover why. We will tour the MCP protocol, the Python reference implementation, and an example agent using an MCP. Expect protocol flow-charts, architecture diagrams, and a real-world demo. You will walk away knowing the core ideas of MCP, how it connects to the broader ecosystem, and how to power your AI agents.
Quasiment toutes les roadmaps Gen AI incluent désormais le déploiement at scale d'assistants experts basés sur des approches RAG. Souvent, la direction prise par les équipes techniques est de considérer chaque assistant comme un projet à part entière, sans suffisamment inclure leur développement et leur maintenance dans un cadre LLMOps bien défini — or c'est ici que le principal obstacle à l'industrialisation d'applications Gen AI se situe, et non sur les capacités des modèles LLM.
Parmi ce cadre, les tests sont indispensables : Context Precision, Context Recall, Faithfulness etc. Les équipes d'Eurazeo et d'Eulidia ont donc mis en place l'automatisation des tests effectués sur les workflows Gen AI, via une intégration de la bibliothèque RAGAS au sein des services Cortex de Snowflake. Cela a permis de poser les bases essentielles pour le déploiement du RAG-as-a-Service, application permettant de créer automatiquement des RAG à destination des équipes internes, tout en garantissant leur performance et leur pertinence.