Registration & Coffee
2025-09-03
Event
Activities tracked
99
Sessions & talks
Showing 26–50 of 99 · Newest first
Social event organized by PyLadies & Empowered in Tech
Location: Hofbräu Wirtshaus, Karl-Liebknecht-Str. 30, 10178 Berlin
We’ll meet outside the BCC at 18

Lightning Talks are short, 5-minute presentations open to all attendees. They’re a fun and fast-paced way to share ideas, showcase projects, spark discussions, or raise awareness about topics you care about — whether technical, community-related, or just inspiring.
No slides are required, and talks can be spontaneous or prepared. It’s a great chance to speak up and connect with the community!

Many industrial and legacy systems still push critical data over TCP streams. Instead of reaching for heavyweight cloud platforms, you can build fast, lean batch pipelines on-prem using Python and DuckDB.
In this talk, you'll learn how to turn raw TCP streams into structured data sets, ready for analysis, all running on-premise. We'll cover key patterns for batch processing, practical architecture examples, and real-world lessons from industrial projects.
If you work with sensor data, logs, or telemetry, and you value simplicity, speed, and control this talk is for you.

How to use LLMs to categorize hundreds of thousands of products into 1,000 categories at scale? Learn about our journey from manual/rule-based methods, via fine-tuned semantic models, to a robust multi-step process which uses embeddings and LLMs via the OpenAI APIs. This talk offers data scientists and AI practitioners learnings and best practices for putting such a complex LLM-based system into production. This includes prompt development, balancing cost vs. accuracy via model selection, testing mult-case vs. single-case prompts, and saving costs by using the OpenAI Batch API and a smart early-stopping approach. We also describe our automation and monitoring in a PySpark environment.
A practical deep-dive into Azure DevOps pipelines, the Azure CLI, and how to combine pipeline, bicep, and python templates to build a fully automated web app deployment system. Deploying a new proof of concept app within an actual enterprise environment never was faster.
With a focus on healthcare applications where accuracy is non negotiable, this talk highlights challenges and delivers practical insights on building AI agents which query complex biological and scientific data to answer sophisticated questions. Drawing from our experience developing Owkin-K Navigator, a free-to-use AI co-pilot for biological research, I'll share hard-won lessons about combining natural language processing with SQL querying and vector database retrieval to navigate large biomedical knowledge sources, addressing challenges of preventing hallucinations and ensuring proper source attribution. This session is ideal for data scientists, ML engineers, and anyone interested in applying python and LLM ecosystem to the healthcare domain.

Evaluating large language models (LLMs) in real-world applications goes far beyond standard benchmarks. When LLMs are embedded in complex pipelines, choosing the right models, prompts, and parameters becomes an ongoing challenge.
In this talk, we will present a practical, human-in-the-loop evaluation framework that enables systematic improvement of LLM-powered systems based on expert feedback. By combining domain expert insights and automated evaluation methods, it is possible to iteratively refine these systems while building transparency and trust.
This talk will be valuable for anyone who wants to ensure their LLM applications can handle real-world complexity - not just perform well on generic benchmarks.

Using AI agents and automation, PyCon DE & PyData volunteers have transformed chaos into streamlined conference ops. From YAML files to LLM-powered assistants, they automate speaker logistics, FAQs, video processing, and more while keeping humans focused on creativity. This case study reveals practical lessons on making AI work in real-world scenarios: structured workflows, validation, and clear context beat hype. Live demos and open-source tools included.

If we want to run data science workloads (e.g. using Tensorflow, PyTorch, and others) in containers (for local development or production on Kubernetes), we need to build container images. Doing that with a Dockerfile is fairly straightforward, but is it the best method? In this talk, we'll take a well-known speech-to-text model (Whisper) and show various ways to run it in containers, comparing the outcomes in terms of image size and build time.

In January the Synthetic Data SDK was introduced and it quickly is gaining traction as becoming the standard Open Source library for creating privacy-preserving synthetic data. In this hands-on tutorial we're going beyond the basics and we'll look at many of the advanced features of the SDK including differential privacy, conditional generation, multi-tables, and fair synthetic data.

This talk presents variational inference as a tool to scale probabilistic models. We describe practical examples with NumPyro and PyMC to demonstrate this method, going through the main concepts and diagnostics. Instead of going heavy into the math, we focus on the code and practical tips to make this work in real industry applications.
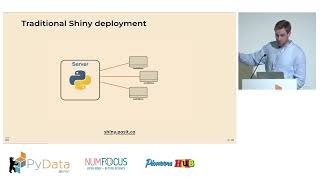
WebAssembly is reshaping how Python applications can be delivered - allowing fully interactive apps that run directly in the browser, without a traditional backend server. In this talk, I’ll demonstrate how to build reactive, data-driven web apps using Shinylive for Python, combining efficient local storage with Parquet and extending functionality with optional FastAPI cloud services. We’ll explore the benefits and limitations of this architecture, share practical design patterns, and discuss when browser-based Python is the right choice. Attendees will leave with hands-on techniques for creating modern, lightweight, and highly responsive Python data applications.

Using LiteLLM in a Real-World RAG System: What Worked and What Didn’t
LiteLLM provides a unified interface to work with multiple LLM providers—but how well does it hold up in practice? In this talk, I’ll share how we used LiteLLM in a production system to simplify model access and handle token budgets. I’ll outline the benefits, the hidden trade-offs, and the situations where the abstraction helped—or got in the way. This is a practical, developer-focused session on integrating LiteLLM into real workflows, including lessons learned and limitations. If you’re considering LiteLLM, this talk offers a grounded look at using it beyond simple prototypes.

Causal inference techniques are crucial to understanding the impact of actions on outcomes. This talk shares lessons learned from applying these techniques in real-world scenarios where standard methods do not immediately apply. Our key question is: What is the causal impact of wealth planning services on a network of individual’s investments and securities? We'll examine the challenges posed by practical constraints and show how to deal with them before applying standard approaches like staggered difference-in-difference.
This self-contained talk is prepared for general data scientists who want to add causal inference techniques to their toolbox and learn from real-world data challenges.

AI agents are having a moment, but most of them are little more than fragile prototypes that break under pressure. Together, we’ll explore why so many agentic systems fail in practice, and how to fix that with real engineering principles. In this talk, you’ll learn how to build agents that are modular, observable, and ready for production. If you’re tired of LLM demos that don’t deliver, this talk is your blueprint for building agents that actually work.