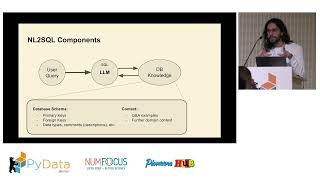
Building and deploying scalable, reproducible machine learning pipelines can be challenging, especially when working with orchestration tools like Slurm or Kubernetes. In this talk, we demonstrate how to create an end-to-end ML pipeline for anomaly detection in International Space Station (ISS) telemetry data using only Python code.
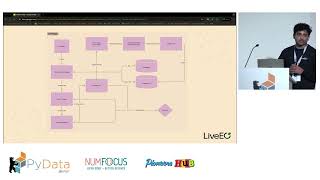
We show how Kubeflow Pipelines, MLFlow, and other open-source tools enable the seamless orchestration of critical steps: distributed preprocessing with Dask, hyperparameter optimization with Katib, distributed training with PyTorch Operator, experiment tracking and monitoring with MLFlow, and scalable model serving with KServe. All these steps are integrated into a holistic Kubeflow pipeline.
By leveraging Kubeflow's Python SDK, we simplify the complexities of Kubernetes configurations while achieving scalable, maintainable, and reproducible pipelines. This session provides practical insights, real-world challenges, and best practices, demonstrating how Python-first workflows empower data scientists to focus on machine learning development rather than infrastructure.