See only what you are allowed to see: Fine-Grained Authorization
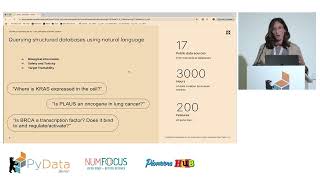
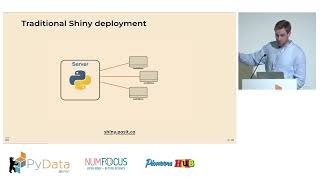
Managing who can see or do what with your data is a fundamental challenge, especially as applications and data grow in complexity. Traditional role-based systems often lack the granularity needed for modern data platforms. Fine-Grained Authorization (FGA) addresses this by controlling access at the individual resource level. In this 90-minute hands-on tutorial, we will explore implementing FGA using OpenFGA, an open-source authorization engine inspired by Google's Zanzibar. Attendees will learn the core concepts of Relationship-Based Access Control (ReBAC) and get practical experience defining authorization models, writing relationship tuples, and performing authorization checks using the OpenFGA Python SDK. Bring your laptop ready to code to learn how to build secure and flexible permission systems for your data applications.