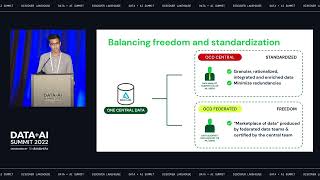
Orchestration Made Easy with Databricks Workflows
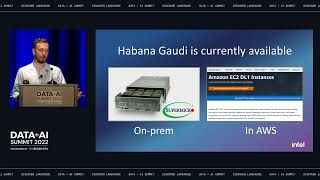
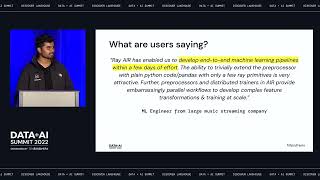
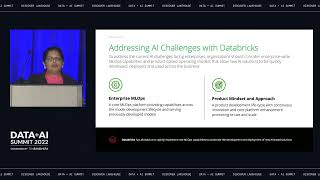
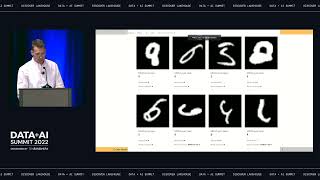
Orchestrating and managing end-to-end production pipelines have remained a bottleneck for many organizations. Data teams spend too much time stitching pipeline tasks and manually managing and monitoring the orchestration process – with heavy reliance on external or cloud-specific orchestration solutions, all of which slow down the delivery of new data. In this session, we introduce you to Databricks Workflows: a fully managed orchestration service for all your data, analytics, and AI, built in the Databricks Lakehouse Platform. Join us as we dive deep into the new workflow capabilities, and understand the integration with the underlying platform. You will learn how to create and run reliable production workflows, centrally manage and monitor workflows, and learn how to implement recovery actions such as repair and run, as well as other new features.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/