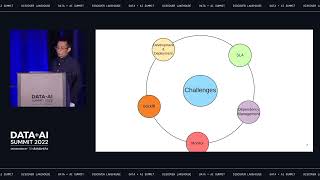
There are more data tools available than ever before, and it is easier to build a pipeline than it has ever been. These tools and advancements have created an explosion of innovation, resulting in data within today's organizations becoming increasingly distributed and can't be contained within a single brain, a single team, or a single platform. Data lineage can help by tracing the relationships between datasets and providing a map of your entire data universe.
OpenLineage provides a standard for lineage collection that spans multiple platforms, including Apache Airflow, Apache Spark™, Flink®, and dbt. This empowers teams to diagnose and address widespread data quality and efficiency issues in real time. In this session, we will show how to trace data lineage across Apache Spark and Apache Airflow. There will be a walk-through of the OpenLineage architecture and a live demo of a running pipeline with real-time data lineage.
Talk by: Julien Le Dem,Willy Lulciuc
Here’s more to explore: Data, Analytics, and AI Governance: https://dbricks.co/44gu3YU
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc