Reynold Xin, Co-founder and Chief Architect at Databricks, presented during Data + AI Summit 2024 on Databricks SQL and its advancements and how to drive performance improvements with the Databricks Data Intelligence Platform.
Speakers: Reynold Xin, Co-founder and Chief Architect, Databricks Pearl Ubaru, Technical Product Engineer, Databricks
Main Points and Key Takeaways (AI-generated summary)
Introduction of Databricks SQL: - Databricks SQL was announced four years ago and has become the fastest-growing product in Databricks history. - Over 7,000 customers, including Shell, AT&T, and Adobe, use Databricks SQL for data warehousing.
Evolution from Data Warehouses to Lakehouses: - Traditional data architectures involved separate data warehouses (for business intelligence) and data lakes (for machine learning and AI). - The lakehouse concept combines the best aspects of data warehouses and data lakes into a single package, addressing issues of governance, storage formats, and data silos.
Technological Foundations: - To support the lakehouse, Databricks developed Delta Lake (storage layer) and Unity Catalog (governance layer). - Over time, lakehouses have been recognized as the future of data architecture.
Core Data Warehousing Capabilities: - Databricks SQL has evolved to support essential data warehousing functionalities like full SQL support, materialized views, and role-based access control. - Integration with major BI tools like Tableau, Power BI, and Looker is available out-of-the-box, reducing migration costs.
Price Performance: - Databricks SQL offers significant improvements in price performance, which is crucial given the high costs associated with data warehouses. - Databricks SQL scales more efficiently compared to traditional data warehouses, which struggle with larger data sets.
Incorporation of AI Systems: - Databricks has integrated AI systems at every layer of their engine, improving performance significantly. - AI systems automate data clustering, query optimization, and predictive indexing, enhancing efficiency and speed.
Benchmarks and Performance Improvements: - Databricks SQL has seen dramatic improvements, with some benchmarks showing a 60% increase in speed compared to 2022. - Real-world benchmarks indicate that Databricks SQL can handle high concurrency loads with consistent low latency.
User Experience Enhancements: - Significant efforts have been made to improve the user experience, making Databricks SQL more accessible to analysts and business users, not just data scientists and engineers. - New features include visual data lineage, simplified error messages, and AI-driven recommendations for error fixes.
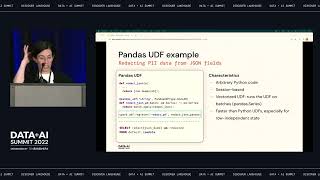
AI and SQL Integration: - Databricks SQL now supports AI functions and vector searches, allowing users to perform advanced analysis and query optimizations with ease. - The platform enables seamless integration with AI models, which can be published and accessed through the Unity Catalog.
Conclusion: - Databricks SQL has transformed into a comprehensive data warehousing solution that is powerful, cost-effective, and user-friendly. - The lakehouse approach is presented as a superior alternative to traditional data warehouses, offering better performance and lower costs.