Comcast Effectv, the 2,000-employee advertising wing of Comcast, America’s largest telecommunications company, provides custom video ad solutions powered by aggregated viewership data. As a global technology and media company connecting millions of customers to personalized experiences and processing billions of transactions, Comcast Effectv was challenged with handling massive loads of data, monitoring hundreds of data pipelines, and managing timely coordination across data teams.
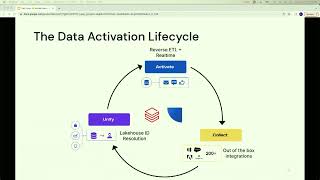
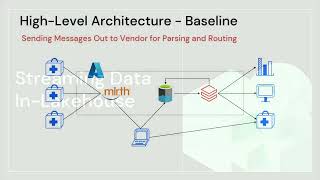
In this session, we will discuss Comcast Effectv’s journey to building a more scalable, reliable lakehouse and driving data observability at scale with Monte Carlo. This has enabled Effectv to have a single pane of glass view of their entire data environment to ensure consumer data trust across their entire AWS, Databricks, and Looker environment.
Talk by: Scott Lerner and Robinson Creighton
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc