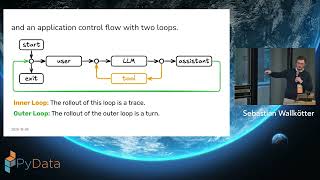
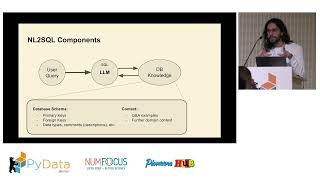
Multi-agent AI systems now orchestrate complex workflows requiring frequent foundation model calls. In this session, learn how you can reduce latencies to single-digit milliseconds from single-digit seconds with vector search for Amazon ElastiCache for Valkey in agentic AI applications using semantic caching, while also reducing the cost incurred from your foundation models for production workloads. By implementing semantic caching in agentic architectures like RAG-powered assistants and autonomous agents, customers can create performant and cost-effective production-scale agentic AI systems.
Learn More: More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.