Instacart has gone through immense growth during the pandemic and the trend continues. Instacart ads is no exception in this growth story. We have launched many new product lines including display and video ads covering the full advertising funnel to address the increasing demand of our retail partners. We have built advanced models to auto-suggest optimal bidding to increase the ROI for our CPG partners. Advertisers’ trust is the utmost priority and thus the quest to build a top-class ads measurement platform.
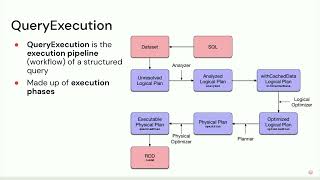
Ads data processing requires complex data verifications to update ads serving stats. In ETL pipelines these were implemented through files containing thousands of lines of raw SQL which were hard to scale, test, and iterate upon. Our data engineers used to spend hours testing small changes due to a lack of local testing mechanisms. These pain points stress our need for better tools. After some research, we chose Apache Spark™ as our preferred tool to rebuild ETLs, and the Databricks platform made this move easier. In this session, We'll share our journey to move our pipelines to Spark and Delta Lake on Databricks. With Spark, Scala, and Delta we solved many problems which were slowing the team’s productivity. Some key areas that will be covered include:
- Modular and composable code
- Unit testing framework
- Incremental event processing with spark structured streaming
- Granular resource tuning for better performance and cost efficacy
Other than the domain business logic, the problems discussed here are quite common for performing data processing at scale. We hope that sharing our learnings will benefit others who are going through similar growth challenges or migrating to Lakehouse.
Talk by: Devlina Das and Arthur Li
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc