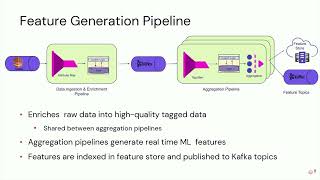
Data with low latency is important for real-time incident analysis and metrics. Though we have up-to-date data in OLTP databases, they cannot support those scenarios. Data need to be replicated to a data warehouse to serve queries using GroupBy and Join across multiple tables from different systems. At Coinbase, we designed SOON (Spark cOntinuOus iNgestion) based on Kafka, Kafka Connect, and Apache Spark™ as an incremental table replication solution to replicate tables of any size from any database to Delta Lake in a timely manner. It also supports Kafka events ingestion naturally.
SOON incrementally ingests Kafka events as appends, updates, and deletes to an existing table on Delta Lake. The events are grouped into two categories: CDC (change data capture) events generated by Kafka Connect source connectors, and non-CDC events by the frontend or backend services. Both types can be appended or merged into the Delta Lake. Non-CDC events can be in any format, but CDC events must be in the standard SOON CDC schema. We implemented Kafka Connect SMTs to transform raw CDC events into this standardized format. SOON unifies all streaming ingestion scenarios such that users only need to learn one onboarding experience and the team only needs to maintain one framework.
We care about the ingestion performance. The biggest append-only table onboarded has ingress traffic at hundreds of thousands events per second; the biggest CDC-merge table onboarded has a snapshot size of a few TBs and CDC update traffic at hundreds of thousands events per second. A lot of innovative ideas are incorporated in SOON to improve its performance, such as min-max range merge optimization, KMeans merge optimization, no-update merge for deduplication, generated columns as partitions, etc.
Talk by: Chen Guo
Here’s more to explore:
Big Book of Data Engineering: 2nd Edition: https://dbricks.co/3XpPgNV
The Data Team's Guide to the Databricks Lakehouse Platform: https://dbricks.co/46nuDpI
Connect with us: Website: https://databricks.com
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/databricks
Instagram: https://www.instagram.com/databricksinc
Facebook: https://www.facebook.com/databricksinc