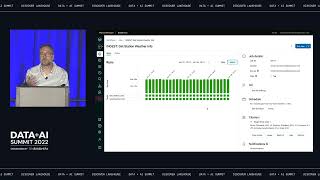
Data engineering is a requirement for any data, analytics or AI workload. With the increased complexity of data pipelines, the need to handle real-time streaming data and the challenges of orchestrating reliable pipelines, data engineers require the best tools to help them achieve their goals. The Databricks Lakehouse Platform offers a unified platform to ingest, transform and orchestrate data and simplifies the task of building reliable ETL pipelines.
This session will provide an introductory overview of the end-to-end data engineering capabilities of the platform, including Delta Live Tables and Databricks Workflows. We’ll see how these capabilities come together to provide a complete data engineering solution and how they are used in the real world by organizations leveraging the lakehouse turning raw data into insights.
Talk by: Jibreal Hamenoo and Ori Zohar
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc