Dive Deeper into Data Engineering on Databricks
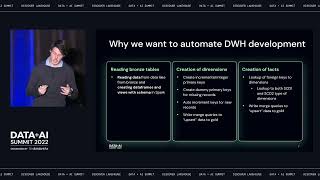
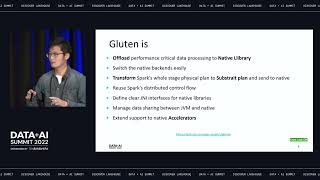
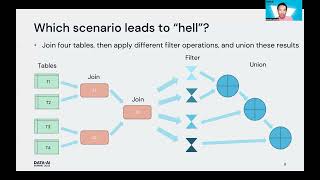
To derive value from data, engineers need to collect, transform, and orchestrate data from various data types and source systems. However, today’s data engineering solutions support only a limited number of delivery styles, involve a significant amount of hand-coding, and have become resource-intensive. Modern data engineering requires more advanced data lifecycle for data ingestion, transformation, and processing. In this session, learn how the Databricks Lakehouse Platform provides an end-to-end data engineering solution — ingestion, processing and scheduling — that automates the complexity of building and maintaining pipelines and running ETL workloads directly on a data lake, so your team can focus on quality and reliability to drive valuable insights.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/