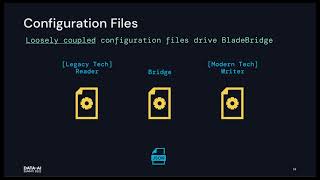
dbt has done a great job of building an elegant, common interface between data engineers and data analysts: uniting on SQL. As the data industry evolves, there's plenty of pain and room to grow in building that interface between data scientists and data analysts. There isn't a good answer for when things go wrong in the machine learning arena: should the data analyst own fine-tuning the pre-processing data(think: prepping transformed data even more for machine learning models to better work with the data). Should we increase the SQL surface area to build ML models or should we leave that to non-SQL interfaces(python/scala/etc.)? Does this have to be an either/or future? Whatever the interface evolves into, it must center people, create a low bar and high ceiling, and focus on outcomes and not the mystique of features/tools behind a learning curve.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/