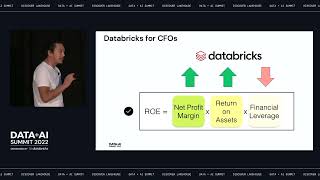
Interactive Analytics on a Massive Scale Using Delta Lake
Interactive, Near Real Time analytics is usually a common requirement for many data teams across different fields.
In the field of web security, interactive analytics allows end users to get real time or historical insights about the state of their protected resource at any point of time and take actions accordingly.
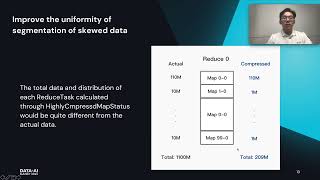
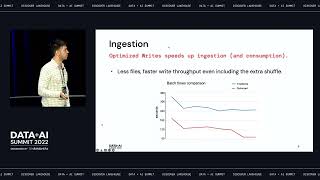
One of the hardest aspects of enabling interactive, near-real-time analytics on a massive scale is a low response time. Scanning hundreds of Terabytes of data over a non-aggregated stream of events (a Delta Lake), and still returning an answer within just a few seconds can be a major challenge.
In this talk we will learn: • How did we build a 5PB Delta Lake of non-aggregated security events • What challenges did we see along the way - reducing delta log scan, improving cache affinity, reducing storage throttling errors etc. • How did we overcome them one by one
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/