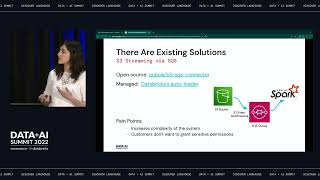
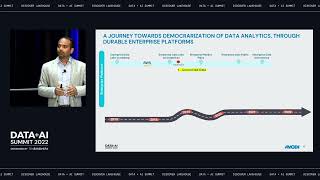
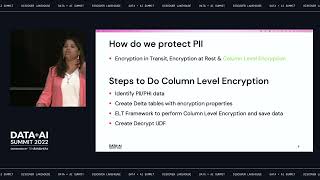
Secure Data Distribution and Insights with Databricks on AWS
Every industry must comply with some form of compliance or data security in order to operate. As data becomes more mission critical to the organization, so does the need to protect and secure it.
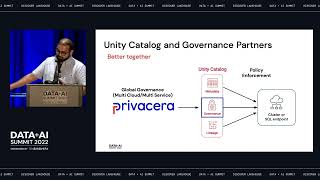
Public Sector organizations are responsible for securing sensitive data sets and complying with regulatory programs such as HIPAA, FedRAMP, and StateRAMP.
This does not come as a surprise given the many different attacks targeted at the industry and the extremely sensitive nature of the large volumes of data stored and analyzed. For a product owner or DBA, this can be extremely overwhelming with a security team issuing more restrictions and data access becoming more of a common request among business users. It can be difficult finding an effective governance model to democratize data while also managing compliance across your hybrid estate.
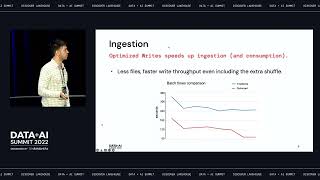
In this session, we will discuss challenges faced in the public sector when expanding to AWS cloud. We will review best practices for managing access and data integrity for a cloud-based data lakehouse with Databricks, and discuss recommended approaches for securing your AWS Cloud environment. We will highlight ways to enable compliance by developing a continuous monitoring strategy and providing tips for implementation of defense in depth. This guide will provide critical questions to ask, an overall strategy, and specific recommendations to serve all security leaders and data engineers in the Public Sector.
This talk is intended to educate on security design considerations when extending your data warehouse to the cloud. This guidance is expected to grow and evolve as new standards and offerings emerge for local, state, and federal government.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/