Unlocking the Value of Data Sharing in Financial Services with Lakehouse
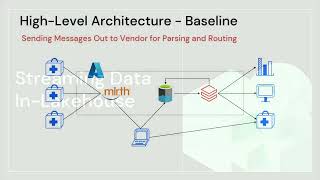
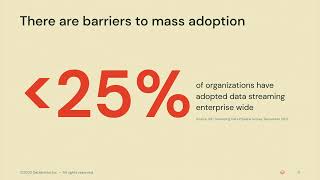
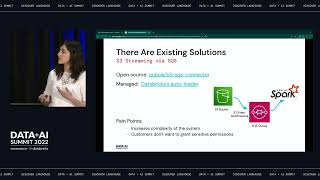
The emergence of secure data sharing is already having a tremendous economic impact, in large part due to the increasing ease and safety of sharing financial data. McKinsey predicts that the impact of open financial data will be 1-4.5% of GDP globally by 2030. This indicates there is a narrowing window on a massive opportunity for financial institutions and it is critical that they prioritize data sharing. This session will first address the ways in which Delta Sharing and Unity Catalog on a Databricks Lakehouse architecture provides a simple and open framework for building a Secure Data Sharing platform in the financial services industry. Next we will use a Databricks environment to walk through different use cases for open banking data and secure data sharing, demonstrating how they will be implemented using Delta Sharing, Unity Catalog, and other parts of the Lakehouse platform. The use cases will include examples of new product features such as Databricks to Databricks sharing, change data feed and streaming on Delta Sharing, table/column lineage, and the Delta Sharing Excel plugin to demonstrate state of the art sharing capabilities.
In this session, we will discuss secure data sharing on Databricks Lakehouse and will demonstrate architecture and code for common sharing use cases in the finance industry.
Talk by: Spencer Cook
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc