A Practitioner's Guide to Unity Catalog—A Technical Deep Dive
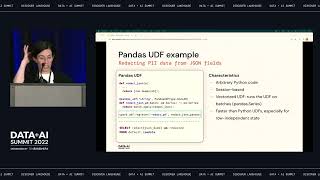
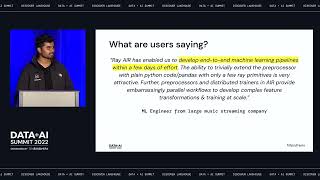
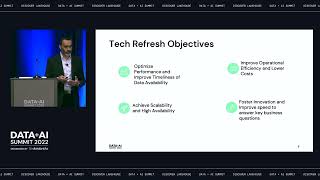
As a practitioner, managing and governing data assets and ML models in the data lakehouse is critical for your business initiatives to be successful. With Databricks Unity Catalog, you have a unified governance solution for all data and AI asserts in your lakehouse, giving you much better performance, management and security on any cloud. When deploying Unity Catalog for your lakehouse, you must be prepared with best practices to ensure a smooth governance implementation. This session will cover key considerations for a successful implementation such as: • How to manage Unity Catalog’s metastore and understand various usage patterns • How to use identity federation to assign account principals to a Databricks Workspace • Best practices for leveraging cloud storages, managed tables and external tables with Unity catalog
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/