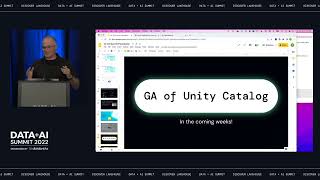
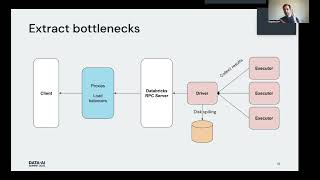
CARTO’s Spatial Extension provides the fundamental building blocks for Location Intelligence in Databricks. Many of the largest organizations using CARTO leverage Databricks for their analytics. Customers very often build custom spatial applications that simplify either a spatial analysis use case or provide a more direct interface to access business intelligence or information. CARTO facilitates the creation of these apps with a complete set of development libraries and APIs. For visualization, CARTO makes use of the powerful deck.gl visualization library. You utilize CARTO Builder to design your maps and perform analytics using Spatial SQL similar to PostGIS, but with the scalability of Apache Spark and then you reference them in your code. CARTO will handle visualizing large datasets, updating the maps, and everything in between. In this talk we will walk you through the process to build spatial applications with CARTO hosted in Apache Spark.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/