ABOUT THE TALK:
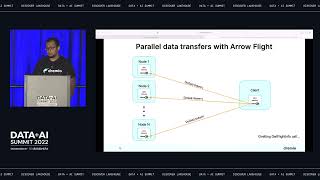
In this talk, we'll dive into one of the newest Apache Arrow subprojects, Arrow Database Connectivity (ADBC), an API specification for Arrow-based database access.
Over the course of this session, you’ll get a crash course in ADBC and learn how it communicates with different data APIs (like Arrow Flight SQL and Postgres) using Arrow-native in-memory data. By the end, you’ll understand the use cases it can conquer and know where to access the resources you need to get started.
This talk will cover goals, use-cases, and examples of using ADBC to communicate with different Data APIs (such as Flight SQL or postgres) with Arrow Native in-memory data.
ABOUT THE SPEAKER:
Matthew Topol is a committer for the Apache Arrow project, frequently enhancing the Golang Arrow and Parquet libraries among other enhancements and helping to grow the Arrow Community. Recently, Matt has joined Voltron Data in order to work on the Apache Arrow libraries full time and grow the Arrow Golang community. In June 2022, Matt's first book was published, which is the first (and currently only) book on Apache Arrow titled "In-Memory Analytics with Apache Arrow".
ABOUT DATA COUNCIL:
Data Council (https://www.datacouncil.ai/) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers.
Make sure to subscribe to our channel for the most up-to-date talks from technical professionals on data related topics including data infrastructure, data engineering, ML systems, analytics and AI from top startups and tech companies.
FOLLOW DATA COUNCIL:
Twitter: https://twitter.com/DataCouncilAI
LinkedIn: https://www.linkedin.com/company/datacouncil-ai/