Today, we’re joined by Vineet Jain, Co-Founder & CEO of Egnyte, the #1 cloud content governance platform. We talk about: The generative AI hype cycleStartups focusing on creating value versus increasing their valuationBiggest challenges to implementing an enterprise content management systemHow to boost user adoption of a new content management systemWill on-prem infrastructure eventually disappear?
 talk-data.com
talk-data.com
Topic
Cloud Computing
infrastructure
saas
iaas
4055
tagged
Activity Trend
471
peak/qtr
2020-Q1
2026-Q2
Top Events
Google Cloud Next '24
911
Google Cloud Next '25
662
O'Reilly Data Engineering Books
499
AWS re:Invent 2024
341
Data Engineering Podcast
237
Microsoft Ignite 2025
227
Databricks DATA + AI Summit 2023
99
O'Reilly Data Science Books
96
Data + AI Summit 2025
86
Dbt Coalesce 2024
86
Making Data Simple
49
Secrets of Data Analytics Leaders
30

Business decisions in any context—operational, tactical, or strategic—can have considerable consequences. Whether the outcome is positive and rewarding or negative and damaging to the business, its employees, and stakeholders is unknown when action is approved. These decisions are usually made under the proverbial cloud of uncertainty. With this practical guide, data analysts, data scientists, and business analysts will learn why and how maximizing positive consequences and minimizing negative ones requires three forms of rich information: Descriptive analytics explores the results from an action—what has already happened. Predictive analytics focuses on what could happen. The third, prescriptive analytics, informs us what should happen in the future. While all three are important for decision-makers, the primary focus of this book is on the third: prescriptive analytics. Author Walter R. Paczkowski, Ph.D. shows you: The distinction among descriptive, predictive, and prescriptive analytics How predictive analytics produces a menu of action options How prescriptive analytics narrows the menu of action options The forms of prescriptive analytics: eight prescriptive methods Two broad classes of these methods: non-stochastic and stochastic How to develop prescriptive analyses for action recommendations Ways to use an appropriate tool-set in Python
Summary The rapid growth of generative AI applications has prompted a surge of investment in vector databases. While there are numerous engines available now, Lance is designed to integrate with data lake and lakehouse architectures. In this episode Weston Pace explains the inner workings of the Lance format for table definitions and file storage, and the optimizations that they have made to allow for fast random access and efficient schema evolution. In addition to integrating well with data lakes, Lance is also a first-class participant in the Arrow ecosystem, making it easy to use with your existing ML and AI toolchains. This is a fascinating conversation about a technology that is focused on expanding the range of options for working with vector data. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm interviewing Weston Pace about the Lance file and table format for column-oriented vector storageInterview IntroductionHow did you get involved in the area of data management?Can you describe what Lance is and the story behind it?What are the core problems that Lance is designed to solve?What is explicitly out of scope?The README mentions that it is straightforward to convert to Lance from Parquet. What is the motivation for this compatibility/conversion support?What formats does Lance replace or obviate?In terms of data modeling Lance obviously adds a vector type, what are the features and constraints that engineers should be aware of when modeling their embeddings or arbitrary vectors?Are there any practical or hard limitations on vector dimensionality?When generating Lance files/datasets, what are some considerations to be aware of for balancing file/chunk sizes for I/O efficiency and random access in cloud storage?I noticed that the file specification has space for feature flags. How has that aided in enabling experimentation in new capabilities and optimizations?What are some of the engineering and design decisions that were most challenging and/or had the biggest impact on the performance and utility of Lance?The most obvious interface for reading and writing Lance files is through LanceDB. Can you describe the use cases that it focuses on and its notable features?What are the other main integrations for Lance?What are the opportunities or roadblocks in adding support for Lance and vector storage/indexes in e.g. Iceberg or Delta to enable its use in data lake environments?What are the most interesting, innovative, or unexpected ways that you have seen Lance used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on the Lance format?When is Lance the wrong choice?What do you have planned for the future of Lance?Contact Info LinkedInGitHubParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Links Lance FormatLanceDBSubstraitPyArrowFAISSPineconePodcast EpisodeParquetIcebergPodcast EpisodeDelta LakePodcast EpisodePyLanceHilbert CurvesSIFT VectorsS3 ExpressWekaDataFusionRay DataTorch Data LoaderHNSW == Hierarchical Navigable Small Worlds vector indexIVFPQ vector indexGeoJSONPolarsThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
As organizations evolve, many still rely on legacy SQL queries and stored procedures that can become bottlenecks in scaling data infrastructure. In this talk, we will explore how to modernize these workflows by migrating legacy SQL and stored procedures into dbt models, enabling more efficient, scalable, and version-controlled data transformations. We’ll discuss practical strategies for refactoring complex logic, ensuring data lineage, data quality and unit testing benefits, and improving collaboration among teams. This session is ideal for data and analytics engineers, analysts, and anyone looking to optimize their ETL workflows using dbt.
Speaker: Bishal Gupta
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Dive into the technical evolution of Bilt’s data infrastructure as they moved from fragmented, slow, and costly analytics to a streamlined, scalable, and holistic solution with dbt Cloud. In this session, the Bilt team will share how they implemented data modeling practices, established a robust CI/CD pipeline, and leveraged dbt’s Semantic Layer to enable a more efficient and trusted analytics environment. Attendees will gain a deep understanding of Bilt’s approach to data including: cost optimization, enhancing data accessibility and reliability, and most importantly, supporting scale and growth.
Speakers: Ben Kramer Director, Data & Analytics Bilt Rewards
James Dorado VP, Data Analytics Bilt Rewards
Nick Heron Senior Manager, Data Analytics Bilt Rewards
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

by
Neha Hystad
Are you making the most of your dbt Cloud deployment? This session is targeted to Admins and will provide guidance on how to leverage dbt Cloud features and workflows to maximize your team’s ability to efficiently deliver quality data products to the broader organization.
Speaker: Neha Hystad
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Making use of AI in the dbt development lifecycle has the potential to be a massive productivity unlock for your team. In this talk, explore how AI-driven approaches can improve your development process with Michiel De Smet from Altimate AI and Anton Goncharuk from Hubspot. Discover practical strategies to automate your work, prevent issues earlier, and embed best practices. Along the way, you'll also get to hear some real-life examples from how the team at HubSpot streamlined their dbt Cloud development workflow and enhanced collaboration within the team.
Speakers: Michiel De Smet Founding Engineer Altimate AI
Anton Goncharuk Principal Analytics Engineer HubSpot
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Are you a dbt Cloud customer aiming to fast-track your company’s journey to GenAI and speed up data development? You can't deploy AI applications without trusting the data that feeds them. Rule-based data quality approaches are a dead end that leaves you in a never-ending maintenance cycle. Join us to learn how modern machine learning approaches to data quality overcome the limits of rules and checks, helping you escape the reactive doom loop and unlock high-quality data for your whole company.
Speakers: Amy Reams VP Business Development Anomalo
Jonathan Karon Partner Innovation Lead Anomalo
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
In this session Connor will dive into optimizing compute resources, accelerating query performance, and simplifying data transformations with dbt and cover in detail: - SQL-based data transformation, and why is it gaining traction as the preferred language with data engineers - Life cycle management for native objects like fact tables, dimension tables, primary indexes, aggregating indexes, join indexes, and others. - Declarative, version-controlled data modeling - Auto-generated data lineage and documentation
Learn about incremental models, custom materializations, and column-level lineage. Discover practical examples and real-world use cases how Firebolt enables data engineers to efficiently manage complex tasks and optimize data operations while achieving high efficiency and low latency on their data warehouse workloads.
Speaker: Connor Carreras Solutions Architect Firebolt
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
They say lightning never strikes the same place twice... but what does the data say?
Ever wonder if all those widely accepted "truths" about the world are actually true? In this myth-busting session, we'll leverage public datasets and Hex to challenge common beliefs about everything from human behavior to scientific "facts." We'll do a live walkthrough of he entire process: finding the right data, cleaning it up, analyzing it to separate fact from fiction, and making results easily available to explore and use.
We'll tackle myths across crime, sports, society, and of course, lightning, using real data from crowdsourced and government sources. By the end, we'll have set the record straight on those "truths," and you'll have learned new ways to explore data and make it friendlier non-data folks to engage with.
Speakers: Izzy Miller Hex
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Riot Games, creator of hit titles like League of Legends and Valorant, is building an ultimate gaming experience by using data and AI to deliver the most optimal player journeys. In this session, you'll learn how Riot's data platform team paired with analytics engineering, machine learning, and insights teams to integrate Databricks Data Intelligence Platform and dbt Cloud to significantly mature its data capabilities. The outcome: a scalable, collaborative analytics environment that serves millions of players worldwide.
You’ll hear how Riot Games: - Centralized petabytes of game telemetry on Databricks for fast processing and analytics - Modernized their data platform by integrating dbt Cloud, unlocking governance for modular, version-controlled data transformations and testing for a diverse set of user personas - Uses Generative AI to automate the enforcement of good documentation and quality code and plans to use Databricks AI to further speed up its ability to unlock the value of data - Deployed machine learning models for personalized recommendations and player behavior analysis
You'll come away with practical insights on architecting a modern data stack that can handle massive scale while empowering teams across the organization. Whether you're in gaming or any data-intensive industry, you'll learn valuable lessons from Riot's journey to build a world-class data platform.
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

AWS offers the most scalable, highest performing data services to keep up with the growing volume and velocity of data to help organizations to be data-driven in real-time. AWS helps customers unify diverse data sources by investing in a zero ETL future and enable end-to-end data governance so your teams are free to move faster with data. Data teams running dbt Cloud are able to deploy analytics code, following software engineering best practices such as modularity, continuous integration and continuous deployment (CI/CD), and embedded documentation. In this session, we will dive deeper into how to get near real-time insight on petabytes of transaction data using Amazon Aurora zero-ETL integration with Amazon Redshift and dbt Cloud for your Generative AI workloads.
Speakers: Neela Kulkarni Solutions Architect AWS
Neeraja Rentachintala Director, Product Management Amazon
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
In this talk, we explore the challenges and strategies of data teams that have scaled their dbt over 1,000 models and often across multiple projects.
We'll dive into the types of organizations that reach this scale and the common challenges they face. From data democratization efforts to infrastructure and tooling requirements, we'll cover what it takes to effectively manage such a vast and complex dbt environment. What does their team structure look like? What type of processes do they have? What type of automation did they implement to enable efficient data operations at scale?
Whether you're just starting with dbt or looking to manage a growing number of models, this talk is to offer practical insights to help you navigate the complexities of large-scale dbt deployments.
Speaker: Rya Sciban Head of Product Select Star
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
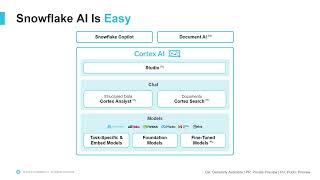
Ready to level up your data pipelines with AI and ML? In this session, we'll dive into key Snowflake AI and ML features and teach you how to easily integrate them into dbt pipelines. You'll explore real-world machine learning and generative AI use cases, and see how dbt and Snowflake together deliver powerful, secure results within Snowflake’s governance and security framework. Plus, discover how data scientists, engineers, and analysts can collaborate seamlessly using these tools. Whether you're scaling ML models or embedding AI into your existing workflows, this session will give you practical strategies for building secure, AI-powered data pipelines with dbt and Snowflake.
Speaker: Randy Pettus Senior Partner Sales Engineer Snowflake
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

At Airbyte, we leverage dbt to power our roadmap - from user discovery to customer retention efforts.
We need to parse across many sources of data across our open-source and Cloud communities, including Gong transcripts, NPS surveys, and Github issues. I'll share examples of how dbt powers how we work - from discovering product gaps and their importance to deals, to building retention tools like custom notifications around customer pipelines.
Speaker: Natalie Kwong Product Airbyte
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Espresso AI uses two main techniques to run dbt workloads substantially faster and cheaper on data warehouses: better job scheduling and automatically incrementalizing queries. This talk will dive into the technical details behind both approaches.
Speaker: Ben Lerner Co-founder and CEO Espresso AI
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
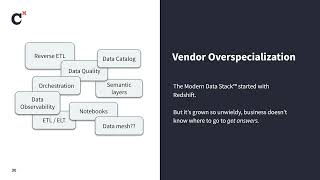
The modern data stack has improved the lives of data teams everywhere. But has it helped the rest of the business? In this talk, we’ll discuss the business teams’ perspective. Are they actually getting value from the modern data stack? How does help it them do their jobs better? And why do data teams keep questioning if we’re “adding value” with our powerful new tools? Attendees will gain perspective on their data ‘customers’ and learn ideas on how to deliver tangible business value.
Speaker: Paul Blankley CTO Zenlytic
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Join us for an insightful session where we delve into the innovative ways the NBA is leveraging Generative AI (GenAI) to revolutionize data insights and transform the world of sports and entertainment analytics.
Speakers: Keelan Smithers Data Product Manager, Analytics Engineering NBA
Mark Hay CTO & Co-Founder TextQL
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

In 2021, semantic layers took the data world by storm—it felt like they came out of nowhere, then everyone was talking about them. Since then, companies have been built (and some have failed) on the promise of the semantic layer, blog posts have debated their rise and fall, and data teams are still left wondering: was it all just hype, or are semantic layers truly the next big thing in data? In this talk, I'll explore the evolution of the semantic layer and answer the burning question: Is it here to stay, or is it just a passing trend?
Speaker: Katie Hindson Head of Product and Data Lightdash
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Unlock the potential of serverless data transformations by integrating Amazon Athena with dbt (Data Build Tool). In this presentation, we'll explore how combining Athena's scalable, serverless query service with dbt's powerful SQL-based transformation capabilities simplifies data workflows and eliminates the need for infrastructure management. Discover how this integration addresses common challenges like managing large-scale data transformations and needing agile analytics, enabling your organization to accelerate insights, reduce costs, and enhance decision-making.
Speakers: BP Yau Partner Solutions Architect AWS
Darshit Thakkar Technical Product Manager AWS
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements